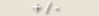Zu Beginn wird von dem Projektleiter (Projektverantwortlicher) ein Projektplan erstellt. In dieser ersten Version des Projektplans müssen alle Aktivitäten enthalten, sowie gewisse Abschätzungen bezüglich Dauer und Aufwand des Projekts aufgenommen werden. Fällt die Entscheidung für die Ausführung des Projekts, so muß dann der eigentliche Projektplan von dem Projektleiter erstellt werden. Er muß sich dabei mit verschiedenen anderen Personen oder Personengruppen beraten.
Bei größeren Projekten muß eine Teilung in einen Gesamtprojektplan und in Detailprojektpläne vorgenommen werden.
Der Gesamtprojektplan sollte unter anderem folgende Informationen enthalten:
· Eine Beschreibung der Aufgabenstellung des Projekts
· Die verwendete Entwicklungsmethode
· Festlegung von Hauptmeilensteinen
· Eine Zerlegung des Gesamtprojekts in Teilprojekte (für die es jeweils einen Detailprojektplan gibt)
· Einen Zeitplan mit den wichtigsten Terminen
· Wichtige zeitliche Abhängigkeiten (Netzplan)
· Eine Personalübersicht
· Eine Übersicht über die benötigten Ressourcen (Betriebsmittel, usw.)
Ein Detailprojektplan sollte enthalten:
· Eine Zerlegung des (Teil-) Projekts in Teilaufgaben
· Eine kurze Beschreibung dieser Teilaufgaben und ihrer Endprodukte
· Start- und Fertigstellungstermine für die Teilaufgaben
· Zuordnung der Verantwortlichkeit für die einzelnen Teilaufgaben
· Zuteilung von Ressourcen zu den einzelnen Teilaufgaben bzw. zu den verantwortlichen Personen
Ein Projektplan entwickelt sich im Laufe eines Projekts schrittweise:
Zu Beginn wird ein Übersichtsprojektplan mit den Hauptmeilensteinen erstellt. Die erste Version des eigentlichen Projektplans enthält dann eine genaue Planung aller Schritte bis zum nächstfolgenden Meilenstein, bei dem die nächste Version des Projektplans fällig ist, die dann weitere genaue Planungen enthält.
Die Definition eines Meilensteines in einem Projektplan muß drei Punkte enthalten:
· Die Produkte, die zu diesem Meilenstein fertig sind
· Den Termin für diesen Meilenstein
· Die Kontrollverfahren, die auf die Produkte des Meilensteins angewandt werden
Der Projektplan definiert die Arbeit und wie sie zu machen ist. Er ist mit einer Definition von jeder Hauptaufgabe, einer Schätzung der Zeit und der Ressourcen die benötigt werden, sowie einer Rahmenarbeit für die Kontrolle versehen.
Der Projektplan wird am Anfang des Auftrages entwickelt und dann während des Arbeitsprozesses verfeinert. Am Anfang des Projektes sind die Forderungen eher vage und unvollständig.
Mit wenigen Ausnahmen sind anfängliche Betriebsmittelschätzungen und Zeitpläne nicht annehmbar. Dies ist nicht auf die Unerfahrenheit der Programmierer zurückzuschließen, sondern auf die Benutzer die mehr verlangen als sie benötigen.
Faustregel:
Zeitpläne und Schätzung werden zu hoch, wenn nicht die erste Fassung des Planes nur die wesentlichsten Teile beinhaltet.
1. Der Zyklus beginnt mit den wesentlichen Anforderungen.
2. Die Antwort auf die Frage einer Verpflichtung muß lauten:
Ich verstehe ihre Anforderungen und werde einen Plan mit diesen Zielen entwickeln aber keinen wirklichen Plan. Ich kann keine Verpflichtung eingehen.
3. Der Plan muß zuerst in Schlüsselelemente zerlegt werden.
Vom Groben ins Detail - Work Breakdown Structure
4. Die Größe jedes Produktes ist geschätzt.
5. Die benötigten Ressourcen sind geplant.
6. Der Zeitplan wird produziert.
Die Elemente des Softwareprojektplans sind:
1. Ziele:
Sie beschreiben was von wem wie und wann gemacht wird.
2. Work Breakdown Structure (WBS):
Die WBS zerlegt das Projekt in Teile die alle definiert, geschätzt und verfolgt werden können.
3. Produktgrößenschätzung:
Schätzung zu der Produktgröße. Einbezogen werden auch Erfahrungen von früheren Projekten.
4. Ressourcenschätzung:
Schätzung zu den benötigten Ressourcen. Es fließen auch Erfahrungen bezüglich des Produktionsfaktors ein.
5. Projekt-Zeitplan:
Basierend auf die Projektbelegschaft- und Ressourcenschätzungen. Ein Zeitplan für die Teilpläne wird erstellt.
Die Ziele des Projekts werden während der Bedingungsphase entwickelt. Dies ist auch die Verhandlungsphase in welcher die Softwareentwickler und der Kunde beschreiben was gemacht wird, wie der Erfolg gemessen wird und wieviel Zeit und Ressourcen benötigt werden.
Um weitere Wünsche der Kunden berücksichtigen zu können, müssen die Entwickler folgende Punkte einhalten:
· Das Produkt muß in kleinen zunehmenden Schritten realisiert werden.
· Auswahl jeder Steigerung zur Unterstützung des Erfolgs u/o verbessern des Wissens.
· Festlegen der Bedingungen für jeden zunehmenden Schritt vor dem Beginnen des Designs.
· Wenn sich die Bedingungen während der Einführung ändern, verzögern die Anderungen die nachfolgenden Objekt.
Projektplanung beginnt mit der Schätzung von der Größe des Produktes. Diese Schätzung beginnt mit einer detaillierten und dokumentierten Auflistung des Produktes in Arbeitselemente. Die Auflistung besteht aus zwei Elementen die Produktstruktur und der Software Prozeß.
Die Arbeitselemente werden den verschiedenen Abteilungen zugeordnet. Das Ziel der WBS ist es, das Projekt in kleine Teile aufzuteilen, um diese dann von kleinen Arbeitsgruppen in der kürzesten Zeit zu erledigen.
Generell gilt:
Je detaillierter die WBS ist, desto besser können die Produkte geschätzt werden, desto besser ist der Projektplan, desto besser kann man es verfolgen.
Man kann viel über die Softwaregröße diskutieren, aber es gibt wahrscheinlich keine optimale Lösung die sämtliche Ziele beinhaltet. Es ist weit verbreitet, die Größe des Sourcecodes zu definieren und Berechnungen zu automatisieren. Leider ist es aber oft schwer, Zeilen von Funktionen bereits vorher zu beschreiben. Um dieses Problem zu lösen wurden die sogenannten Function Points entwickelt.
Mit Function Points sind anfängliche Anwendungen zu bestimmen, sowie die Anzahl und Komplexität der verschiedenen Eingaben und Ausgaben, Kalkulationen und der benötigten Daten.
Vorgangsweise:
1. Zählen der Eingaben, Ausgaben, Nachfragen, Hauptfelder und der benötigten Schnittstellen.
2. Multiplizieren der Zahlen mit den folgenden Faktoren:
|
Eingaben |
4 |
|
Ausgaben |
5 |
|
Nachfragen |
4 |
|
Hauptfelder |
10 |
|
Schnittstellen |
10 |
3. Ausgleichen der Summen auf +/-25%, abhängend von der geschätzten Komplexität des Projektes.
Aufwandsschätzung ist ein Muß bei jedem Softwareprojekt, da einem leider keine uneingeschränkten Ressourcen (Zeit und Geld) zur Verfügung stehen. Ein weitverbreitetes Schätzverfahren ist die Delphi-Methode.
Experten geben unabhängig voneinander Schätzungen ab. die Ergebnisse werden durch neuerliches Befragen abgeglichen. Das Delphi-Verfahren ist eine generelle Prognose nicht nur für Softwareprojekte.
1) Koordinator präsentiert jeden Experten die Spezifikation und ein Schätzformular
2) Treffen aller Experten zur Diskussion der Aufgabenstellung und der Schätzung
3) Die Experten füllen unabhängig voneinander die Schätzformulare aus
4) Der Koordinator verteilt eine Zusammenfassung der Schätzungen auf einem Wiederholformular
5) In einem Gruppentreffen werden die Punkte mit unterschiedlicher Expertenmeinung diskutiert
6) Die Experten füllen neuerlich unabhängig voneinander die Schätzformulare aus
Die Schritte 4) bis 6) werden so oft wie nötig wiederholt.
Die Schwierigkeit der Aufwandsschätzung steigt mit dem Umfang des Projekts, und sinkt mit dem Projektfortschritt (je fortgeschrittener die Projektphase, desto genauer wird die Schätzung).
Wenn bereits Schätzungen über den verwendeten Sourcecode vorliegen, so können die Werte in Programmierermonaten (Mannmonaten) und in die benötigte Zeit umgerechnet werden. Diese Produktionsfaktoren können im Durchschnitt in Mannmonaten produziert werden. Produktionsfaktoren können z.B. die Codewachstumsrate sein.
|
Umgebungsfaktoren |
obere 25% |
untere 25% |
Gesamt |
|
zugeteilte Arbeitsfläche (feet ²) |
78 |
46 |
63 |
|
ruhiger Arbeitsplatz |
57% |
29% |
42% |
|
privater Arbeitsplatz |
62% |
19% |
39% |
|
stilles Telefon |
52% |
10% |
29% |
|
Umleitung der Telefonate |
76% |
19% |
57% |
|
unnötige Unterbrechungen |
38% |
76% |
62% |
|
Gefühl der Anerkennung |
57% |
29% |
45% |
Firmen können/müssen ihre eigenen Produktionsfaktoren entwickeln. Diese ergeben sich durch das Prüfen von den Zahlen der kürzlich erzeugten Programme, sowie dem Zählen der Codezeilen in einer konsequenten und definierten Art und Weise. Weiters kann man die Faktoren durch kalkulieren der benötigten Mannmonate für ein Projekt erhalten.
Seit Softwarefirmen ihre Arbeit generell aufgezeichnet haben, ist der erste Schritt in der Entwicklung von Produktionsdaten zu erfahren, was vorhanden ist. Mit dieser Information sollte die folgende Annäherung produziert werden:
1. Identifizieren einer Anzahl von bereits vorhandenen Programmen die mit dem Projekt vergleichbar sind.
2. Daten über die Größe des Codes zu bekommen.
3. Für veränderte Programme sollte nur der Prozentsatz des veränderten Codes und die Nummer der Codelinie aufgezeichnet werden.
4. Erhalten der Mannmonate für das Projekt.
Wenn die Anzahl aller benötigten Ressourcen ausgerechnet worden ist, kann der Zeitplan entwickelt werden. Die Ressourcen werden dabei über die Entwicklungsphasen verteilt.
Sind einmal die benötigten Betriebsmittel bekannt, so kann ein gesamter Zeitplan wie folgt erstellt werden:
· Basierend auf alle Projektzeitpläne kann ein Angestelltenplan erstellt werden.
· Ein vorbereitender Zeitplan für jede Phase kann durch Vergleich der anwachsenden benötigten Ressourcen erstellt werden. Ein anfänglicher Zeitplan entsteht.
· Dieser vorbereitende Plan wird überholt und die Angestellten können fest zugewiesen werden. Anderungen sind meist erforderlich.
Mehrere Checkpoints müssen für jede Projektphase festgelegt werden. Diese sollten wie folgt lauten:
· Modulspezifikation fertiggestellt und geprüft
· Moduldesign fertiggestellt, geprüft und korrigiert
· Moduleinheit Testplan fertiggestellt, überarbeitet und bestätigt
· Modulcode fertiggestellt und kompiliert
· Modulcode geprüft und korrigiert
· Modul wird in System integriert
Nach Erstellung der Schätzung und des Zeitplans wird der volle Entwicklungsplan erstellt und überprüft.
Nach der Vorbereitung wird der Plan in jede eingebundene Stelle geschickt, überprüft und bestätigt. Jede Gruppe muß mit dem Plan einverstanden sein, denn er repräsentiert ihre Verpflichtungen wie und in welcher Zeit sie die Arbeit vollbringen. Er beinhaltet:
· Software Engineering
· Dokumentation
· Test und Testbericht
· Verpackung und Version
· Tools und Support
· Training
· Installationssupport
· Wartung
· Annahmetest
· Software Qualitätssicherung
Der Projektplan beinhaltet jede Hauptaufgabe, eine Schätzung der Zeit und der benötigten Ressourcen, und eine Rahmenarbeit für die Überwachung und Kontrolle. Er wird am Anfang jedes Projektes erstellt und während des Projektes verfeinert.
Die Elemente eines Softwareplans sind:
· Ziele
· ein abgerundetes Design
· Work Breakdown Structure (WBS)
· Schätzung der Produktgröße
· Schätzung der Ressourcen
· und ein Projektzeitplan
Nach der Erstellung der Zeitpläne und der Schätzungen wird der Entwicklungsplan erstellt und von jeder Stelle geprüft und abgezeichnet.
- Zielfestlegung
- Zerlegung in Teilaufgaben: Word Breakdown Structure (WBS)
- Zeitplanung
° Teilsysteme, Aufgaben
° Einplanung von Analyse, Tests und Dokumentation, Schulung, Installation, Qualitätssicherung, Codeinspektion, Reviews
- verwenden von Methoden, SW
- Netzplan
- Meilensteine
- Aufwandsschätzung (Delphi-Methode)
- Einflußfaktor
- Umleitung von Telefonaten
Wozu dient sie ?
Sie wird dazu benötigt, um den Aufwand eines Software-Projekts zu ermitteln. Dies geschieht, da dieser eine zentrale Bedeutung zwischen Auftraggeber und Auftragnehmer hat.
- Funktionalität
- Datenbasis
Meist jedoch ist dieses Fachkonzept zu wenig detailliert.
T Bewertung des Fachkonzepts (mit Hilfe von z.B.: SETec - Methode)
SETec - Methode:
Der Kern wird einer kritischen Analyse mit gewissen Maßstäben unterzogen.
Falls dies nicht mit SETec erfolgt, wird ein erfahrener Projektmanager oder ein
computerunterstütztes Wissenssystem herangezogen, um die Anzahl der
"wahren" Funktionen und Datenobjekte zu errechnen.
- Funktion Point Methode
- Vergleich eines Projektes aus dem Archiv mit dem zu erstellendem Projekt
- Delphi-Methode
- Einzelne Manager werden getrennt voneinander mit den Unterlagen und Informationen konfrontiert.
- Danach schätzt jeder Manager den Aufwand nach seinen Erfahrungen.
- Schließlich werden gemeinsam in einem Review die Ergebnisse analysiert, um einen akzeptablen Mittelwert zu erhalten.
- Bewertung von Informations-Systemen
- Weitergabe dieser Bewertung
- Weitergabe der Erfahrungen von positiven oder negativen Einflüssen aus der Projektarbeit
- einheitliche Anwendbarkeit
- Unabhängig von personenbezogenen Einwirkungen
- Transparenz der Ergebnisse
- Genauigkeit der Ergebnisse
- u.s.w.
- einheitliche Vorgangsweise bei der Projektierung
- klare Definitionen aller Anforderungen an das Projekt
- gleicher Ausbildungs- und Kenntnisstand der Benutzer
- exakte und einheitliche Abgrenzung bei der Klassifizierung
- sie ist keine Wirtschaftlichkeitsrechnung
- sie ist nicht anwendbar bei Kommunikations-Software oder systemnahe Software-Systeme
Werden unterteilt in :
a) Eingabedaten
z.B.: - Bildschirmeingaben
- Interface-Daten von Anwendern
- Hinzufügen
- Andern
- Löschen
b) Ausgabedaten
z.B.: - Lochkarte, Magnetband, Diskette
- Druckausgabe
- Bildschirmausgabe
- Interface-Daten an andere Anwendungen
c) Datenbestände
Jeder Datenbestand, der von der Anwendung
|
} |
- gelesen
- geändert Update-Funktionen
- gelöscht
|
} |
- geschützt
- geladen Service-Funktionen
- entladen
wird, ist zu zählen.
d) Referenzdaten
z.B.: - Tabellen
e) Abfragen
Es ist jede Abfrage zu zählen, die zu einem Suchen nach Informationen in einem Datenbestand und das Ergebnis der Abfrage dem Benutzer sichtbar wird.
Diese 5 Bereich werden dann bewertet.
Werden unterteilt in :
a) Schnittstellen mit anderen Anwendungs-Systemen
b) Dezentraler Verarbeitung, Datenverwaltung
c) Transaktionsrate
d) Verarbeitungslogik :
- Rechenoperationen
- Kontrollverfahren
- Ausnahmeregelungen
- Logik
e) Wiederverwendbarkeit in anderen Anwendungen
f) Datenbestandskonvertierungen
g) Benutzerbedingungen
Diese werden wiederum bewertet.
1) Unbewertete Funktion Points = Anzahl · Gewichtung
UFP = Anzahl · Gewichtung
2) Summe der unbewerteten FP
SUFP = UFP1 + UFP2 + . . . + UFP15
3) Summe der sieben Einflußfaktoren
SEF = EF1 + EF2 + . . . + EF7
4) Berechnung des Faktors Einflußgrad
FEG = 0,7 + ( 0,01 · SEF )
5) Produkt des Faktors Einflußgrad und
der Summe der unbewerteten FP = bewertete FP
BFP = FEG · SUFP
Hat man nun diese Summe errechnet, kann man an Hand einer Tabelle
( z.B. von IBM ) den Realisierungsaufwand in BM ablesen.
BM = Bearbeiter-Monat = 130 Arbeitsstunden bei folgenden Voraussetzungen :
- überwiegend zentrale Online - Anwendungen
- Verwendung von höheren Programmiersprachen
- Einsatz separater Testsysteme
- durchschnittliche Personalqualität
- ständige Beteiligung der Anwender bei der Projektentwicklung
- zentrale Projektorganisation
- Einsatz von Entwicklungs - Tools und - Techniken
- Durchführung von Reviews
Function Point Methode von Allan Albrecht (IBM)
- wie lange dauert die Arbeit
- es werden alle Funktionen des Systems abgegangen:
für jede der drei Funktionen 0 - 6 Punkte (=> max. 18)
1. wie kompliziert ist die Eingabe (Faustregeln, Tabellen)
2. wie kompliziert ist die Ausgabe
3. Komplexität der Abfragen (Datenbankzugriffe)
- pro Tabelle: Anzahl der Spalten und Reihen
- Extrapunkte (0 - 60):
° Schnittstellen zu anderen Systemen
° Verteiltheit
° Schnelligkeit
° Komplexität der Logik
° Wiederverwendbarkeit
° Komplexität der Konvertierung vorhandener Datenbanken
° Benutzeroberfläche
- Punkte in Formel einsetzen => Tabelle von Punkten zu Bearbeitungsmonaten
- Vorteile:
° Tabellen sind auf Grund der Erfahrung sehr gut
- Nachteile:
° Vernachlässigung der Entwicklung guter graphischer Oberflächen
° Aufwand des Managements (Testen, Organisieren) nicht beinhaltet
° Erfahrung der Mitarbeiter, Teamarbeit, Arbeitsraum, nicht berücksichtigt
° benötigt Verfahren zur Vollständigkeit der Funktionen (ERD)
In der EDV-Welt hat sich in der Projektplanung eine Unterteilung in sieben Phasen durchgesetzt. Die Phasen gliedern sich wie folgt:
(1) Anforderungsanalyse (2) Spezifikation
(3) Programmentwurf (4) Codierung
(5) Qualitätssicherung (6)Dokumentation
(7) Installation, Betrieb und Wartung
Auch beim Software-Life-Cycle wird die zuvor besprochene Unterteilung in Phasen verwendet, wenngleich sie auch manchmal anders heißen.
MS zum Software-Life-Cycle:
EINE PHASE DARF ERST BEGINNEN, WENN DIE VORHERGEHENDE PHASE ABGESCHLOSSEN, DAS ZWISCHENPRODUKT DERER GEPRÜFT UND AKZEPTIERT IST.
Aktuelle Version des SOFTWARE-LIFE-CYCLES:
(1) Planung (2) Analyse
(3) Entwurf (4) Erstellung
(5) Einführung (6) Betreuung
Hier wird der Informationsbedarf einer zu untersuchenden Organisationseinheit ermittelt und eine Informationsstrategie erarbeitet. Dazu ist es notwendig, die essentiellen Informationen herauszufinden. Informationen sind dann wichtig, wenn sie bei der Erreichung eines Zieles mithelfen. Unter dem Begriff "Informationsprojekt" wird dabei kein Projekt zur Erstellung eines EDV-Systems verstanden. Informationsprojekte sind Ergebnisse einer ersten, groben Strukturierung einer zu untersuchenden Organisation in Funktionsbereiche. Dabei werden diejenigen Funktionen in einem Informationsprojekt zusammengefaßt, in denen weitgehend die gleichen Informationsobjekte verwendet werden.
Nun ist es notwendig, die einzelnen Informationsprojekte, sowohl aus Daten-, als auch aus Prozeß-Sicht, weiter zu detaillieren. Folgende Grafik soll dies schemenhaft darstellen. Die Strukturierung erfolgt nach de Marco, mittels Datenflußdiagramm.
Es muß zu jedem Zeitpunkt darauf geachtet werden, daß das Datenmodell und das Prozeßmodell zueinander konsistent sind und bleiben. So müssen also die Regeln der Referential Integrity beachtet werden. Endziel der Analysephase ist es, festzuschreiben, WAS getan werden muß, um aus den richtigen Anfangsdaten die richtigen Ausgabedaten zu bekommen.
In der Analyse-Phase wird auch die Qualität des zu erstellenden Informationssystems festgelegt.
Hier wird festgelegt, WIE das System aufgebaut werden muß, um die richtigen vorhandenen Systemdaten richtig darzustellen. Generell geht es in den Methoden, die dafür herangezogen werden können, darum, das zu entwerfende System in kleine, überschaubare Blöcke, die Module, zu untergliedern. Um die Zusammenhänge zwischen den Modulen klar und eindeutig erarbeiten zu können, werden diese Zusammenhänge graphisch dargestellt. Diese Darstellungen werden STRUCTURE CHARTS genannt.
Die Erstellungsphase selbst ist, vorausgesetzt die Phasen zuvor sind alle ordnungsgemäß abgeschlossen worden, eine verhältnismäßig einfache Aufgabe. Beim Vorliegen einer strukturierten Analyse und eines strukturierten Entwurfs sollten hier keine nennenswerten Probleme mehr auftreten. Die Darstellung der Prozeß- und der Datenseite sind so eindeutig klar, daß diese Aufgabe bei Vorgabe entsprechender Systemparameter und bei Verwendung einer entsprechenden Sprache fast vollständig der Computer übernehmen kann. Auch in dieser Phase muß dokumentiert werden. Für die Tests sollten Referenzbeispiele ausgearbeitet werden, an denen die Fehleranfälligkeit besonders gut überprüft werden kann. Unter anderem wird ein Teil des Tests auch für die Projektabnahme durch den Kunden verwendet.
Die Einführungsphase beinhaltet eine Vielzahl von Aktivitäten, die mit der Erstellung des Informationsystems selbst relativ wenig zu tun haben.
Dazu gehört beispielsweise:
· die Schulung der Anwender
· die Schaffung der aufbauorganisatorischen und ablauforganisatorischen Voraussetzungen für das einzuführende System
· Bereitstellung von User-freundlichen Handbüchern
· die Sicherstellung der dafür erforderlichen Infrastruktur
Eine Möglichkeit, um diesen nicht unerheblichen Kostenfaktor unter Kontrolle zu bekommen, ist der möglichst rasche Einsatz von ablauffähiger Software als Kommunikationsgrundlage. Besonders heikle Teile des Programms werden deshalb modellhaft realisiert, um dem Benutzer die Möglichkeit zu geben, sich konkrete Vorstellungen zu machen und etwaige Fehler möglichst früh zu entlarven. Beginn des Prototypings ist ein Modell. Dies stellt also ein Stück ablauffähiger Software dar, das einige Funktionen ermöglicht und mit einigen wenigen Testdaten arbeiten kann. Ein Prototyp ist dann wieder eine Weiterentwicklung.
Unterschied zur fertigen Software:
geringere Softwarequalität höhere Fehlerrate
unrealistische Performance fehlende Dokumentation
Der User ist nun gefordert mit dem Modell oder dem Prototypen zu experimentieren. Der Prototyp kann dann entweder als Grundlage für das endgültige Programmodul verwendet werden, oder er wird kurzerhand ausgebaut, um selbst dann in einer ausgereiften Version als endgültiges Programmodul verwendet zu werden.
Wie entwickelt man große SW - Produkte
Das erste Dokument das der Entwickler bekommt, ist das Pflichtenheft des Kunden: eine Beschreibung was der Kunde von dem zu entwickelnden System verlangt. Solch ein Dokument enthält gewöhnlich Fehler, Zweideutigkeiten und Versäumnisse. Folglich ist die erste Aufgabe die der Entwickler ausführen muß, die Umschreibung des Dokumentes in eine Systemspezifikation, welche die Ausmaße des Systems beschreibt.
Der erste Schritt ist das Niederschreiben der Proportionen des Systems aus der Sicht des Kunden. Das Dokument, das zu entwerfen ist, heißt das Pflichtenheft und ist eine Beschreibung des Systems in Wörtern und nicht in irgendeiner technischen Sprache. Generell gilt: die Qualität des Pflichtenheftes hängt vom Kunden selbst ab. Ein Kunde der mit der Technologie und den Begriffen nicht vertraut ist, schreibt ein kurzes Heft in dem die Proportionen nur vage beschrieben werden, während ein anspruchsvoller Kunde, der den Umfang des System selbst festlegt, es einfacher macht, eine Systemspezifikation zu erstellen. Dieser Abschnitt beschreibt all jene Probleme, die vom schlimmst möglichen Pflichtenheft ausgehen. Die beiden Hauptkomponenten des Pflichtenheftes sind Funktionen und Einschränkungen.
Probleme beim Lesen des Pflichtenheftes:
1. Das Pflichtenheft soll in einer natürlichen Sprache geschrieben sein. Dies kann oft sehr schwierig sein.
2. Dieses Heft ist sehr oft von Mitarbeitern geschrieben, die mit den technischen Möglichkeiten nicht vertraut sind, und oft unmögliches verlangen, das aber nicht zu realisieren ist.
3. Der Kunde weiß selbst nicht was er von dem zu entwickelnden System verlangen soll und schreibt eine Dokumentation die nur vage beschreibt, was das System können soll.
Ein häufig auftretender Fehler des Kunden in seinem Dokument ist es, es mit Platitudes zu 'verseuchen'. Solche 'leere Sätze', die sehr banal sind, sind jedoch oft schwer zu beschreiben. z.B.: Das System soll benutzerfreundlich sein
Zweideutigkeiten führen zu Unklarheiten, und es könnte zu einer Fehlentwicklung kommen. Eine Reorganisation erfordert viel Zeit und Geld. Anhand dieses Beispiels kann man dies vielleicht besser erklären:
Entwicklungs- & Implementierunganweisungen sind Beispiele für Einschränkungen im Pflichtenheft. Zu viele Einschränkungen können den Entwickler jedoch zu sehr einengen. Man sollte dem Entwickler soviel wie mögliche Lösungswege offen lassen, um so vielleicht bessere Systeme zu bekommen (schnellere Zeiten, weniger Speicherplatz).
Die meisten Fehler in einem Pflichtenheft beinhalten Unterlassungen d.h. ein trivial zu scheinender Teil des Systems nimmt plötzlich Ausmaße an, mit dem man nicht gerechnet hat, und das auch nicht im Pflichtenheft genauer beschrieben ist.
Die Systemspezifikation sollte genau beschreiben was geschieht, wenn man Fehler begeht, oder welche Fehlermeldung erscheint. Dies sind die am häufigst auftretenden Fehler in solch einem Dokument.
Das Beschreiben der Funktionen des Systems kann in verschiedene Abstraktionsebenen aufgeteilt werden. Einige haben eine höhere und andere eine niedrigere Abstraktionsstufe. In einem Pflichtenheft oder in einer Systemspezifikation sollen beide Stufen der Abstraktion enthalten sein. d.h. wichtigere Sachen genauer beschreiben, und unwichtigere mit einer höheren Abstraktionsstufe.
Die ideale Systemspezifikation
1. sollte vollständig sein
2. sollte eindeutig geschrieben sein
3. sollte frei von Entwurfs- & Implementierungsanweisungen sein
4. sollte keine Sätze ohne Inhalt beinhalten
5. sollte Funktionen und Einschränkungen getrennt behandeln
6. sollte sortiert sein.
Einschränkungen sind sehr wichtig, können aber beim Verstehen der Funktion oft hinderlich sein. Die ideale Systemspezifikation sollte (mit hinreichenden Querverbindungen dazwischen) Einschränkungen und Funktionen getrennt behandeln. Es ist ebenso wichtig, daß die Spezifikation hierarchisch nach Funktionen geordnet ist. Die Funktionen an der Spitze der Hierarchie sollten eine hohe Beschreibungsstufe haben.
Eine Funktion in einer hohen hierarchischen Ebene sollte wie folgt gegliedert werden:
- sie sollte genauer beschrieben werden als eine Funktion unter ihr
- es sollte festgehalten werden, welche Daten erforderlich sind
- welche Fehler auftreten können
- und welchen Effekt die Funktion haben soll
Wenn eine Funktion einen zu großen Umfang annimmt, soll man diese in eine oder mehrere Subfunktionen aufteilen. Diese wieder in Sub-Subfunktionen
(Übersichtlichkeit).
1) Lese das Pflichtenheft des Kunden sorgfältig, und schreibe Dir Zweideutigkeiten, Auslassungen und Leersätze heraus.
2) Frage den Kunden was diese Leersätze zu bedeuten haben. Wenn diese jedoch Informationen enthalten (Funktion), müssen sie in die Spezifikation aufgenommen werden.
3) Kläre Auslassungen und Zweideutigkeiten mit dem Kunden und seinen Mitarbeitern.
4) Suche alle Entwurfs- & Implementierungsanweisungen und diskutiere diese mit dem Kunden aus, ob man diese nicht weglassen könnte. Zu klären ist auch, ob es immer notwendig ist, den Kunden zu informieren, wenn man solche Anweisungen weglassen will, wenn diese hinderlich bei der optimalen Systemfindung sind (GELD). Wenn der Kunde und der Entwickler der Meinung sind das gewisse Anweisungen gelöscht werden können, sollten sie das tun.
5) Suche Einschränkungen und Funktionen, und schreibe diese in verschiedenen Teilen der Spezifikation nieder.
6) Untersuche die Funktionen, die im Schritt 5 ausgesondert worden sind, und ordne diese in hierarchischer Reihenfolge.
7) Schreibe die erste Version mit allen Entwurfs- & Implementierungsanweisungen, Einschränkungen und Funktionen.
8) Gib diese Spezifikation den Kunden und bespricht diese mit ihm. Gemäß beinhaltet das Dokument mehrere Fehler. Nach der Besprechung mit dem Kunden schreibe eine neue Spezifikation und gib diese wiederum dem Kunden zur Überprüfung. Dies geschieht solange, bis der Kunde mit der Systemspezifikation vollkommen glücklich ist.
Der letzte Schritt ist das Abzeichnen der Systemspezifikation d.h. der Kunde als auch der Entwickler unterschreiben die Spezifikation des zu entwickelnden Systems, der letzten Version. Wenn dies nicht geschieht besteht die Gefahr, daß der Kunde oder der Entwickler ihre Meinung, in Hinblick auf die Systemspezifikation, ändern und es so zu Zwistigkeiten kommt. Außerdem würde eine Neuüberarbeitung des Dokumentes einen Mehraufwand bedeuten (KOSTEN). Wenn beide unterschrieben haben kann der Prozeß des Systementwurfes beginnen.
Das Hauptprinzip bei der Entwicklung von Softwareprojekten ist es, Fehler zu suchen und sie zu beseitigen. Je weniger Fehler die Systemspezifikation aufzuweisen hat, desto früher ist das zu entwickelnde System fertig, und vielleicht noch wichtiger, desto billiger wird die Entwicklung. Fehler, die bis zum Schluß unentdeckt bleiben, können die Kosten für die Entwicklung ins Unendliche steigen lassen. Darum ist es unbedingt notwendig Fehler so schnell wie möglich, wenn möglich noch während der Analyse und Systemspezifikationsentwicklung, zu finden und zu beseitigen. Die Hauptaufgabe eines Systemcheckers ist es, das System zu testen. Unglücklicherweise kann man aber nicht während der Entwicklung testen, sondern erst danach, wenn der Programmcode verfügbar ist. Folglich braucht man eine andere Möglichkeit. Eine der leistungsfähigsten Methoden ist der Systemspezifikations-Rückblick:
Bei kleineren Projekten ist das ganze nur ein zwangloser Rückblick von zwei bis drei Mitarbeitern. Dabei besteht das Team aus einem Analytiker, der für die Spezifikation verantwortlich ist, und dem Projektleiter. Normalerweise wird der Rückblick nach einer Liste von Fragen abgearbeitet, die in diesem Stadium des Projektes gestellt werden sollten.
Sind die Anforderungen klar formuliert ?
Jede Anforderung sollte auf Klarheit untersucht werden. Zu untersuchen ist aber auch, ob Sätze irgendwie verschachtelt sind. Gibt es Sätze mit mehreren Objekten und Subjekten ?
Gibt es Sätze mit einer Vielzahl von Fürwörtern ? Jede Anforderung sollte unter diesen Gesichtspunkten untersucht werden.
Sind die Anforderungen umgangssprachlich geschrieben ?
Wie schon erwähnt, sollte in den Sätzen so wenig wie möglich mit Fachausdrücken gearbeitet werden, um so eine höhere Verständlichkeit zu erreichen.
Sind zweckmäßige Anforderungen vom Pflichtenheft zur Spezifikation nachvollziehbar ?
d.h. der Entwickler muß das Pflichtenheft des Kunden so durchsuchen und filtern, daß Funktionen und Anforderungen deutlicher und eindeutig herauskommen.
Sind die Anforderungen technisch durchführbar ?
Ein Hauptproblem, das im Pflichtenheft immer wieder auftaucht, ist die Undurchführbarkeit einiger Anforderungen.
z.B.: der Kunde will ein System das schnell antwortet. Will aber nicht zuviel Geld für Arbeitsspeicher ausgeben.
Dies sind zwei Dinge die sich gegenseitig ausschließen. Oft kann das Team die technische Realisierbarkeit nur anhand eines Simulationsprogrammes schätzen.
Sind die Anforderungen prüfbar ?
Dies ist die Frage, die Zweideutigkeiten, eine Menge von Unkomplettheiten und Sätze ohne Inhalt aufspürt. Am Ende des Softwareprojektes muß man eine Reihe von Abnahmetests durchführen. Jede Annahme testet einen anderen Bereich des Systems. Diese Tests entstanden aus der Spezifikation heraus. Jede Funktion und Einschränkung des Systems sollte vom Review-Team genügend getestet werden.
Welche Tests sind für jede Anforderung erforderlich ?
Es gibt eine große Vielzahl von Testmöglichkeiten für Softwareprojekte. Die Programmcodes könnten kontrolliert werden, ob die Funktionen richtig realisiert worden sind. Die Version könnte auf einem langsameren System getestet werden
Es ist nur wichtig, daß die Art des Testes während der Rückschau bekannt ist. Dies ist wichtig, da manche Tests im Echtzeitbetrieb laufen und eine spezielle Hard- bzw. Software benötigen.
Gibt es irgendwelche Entwurfs- und Implementierungsanweisungen ?
Entwurfs- oder Implementierungsanweisungen, die den Entwickler zu sehr einschränken, sollten in dieser Stufe spätestens entfernt werden. Einige werden natürlich bleiben: oft ist es notwendig, ein neues System mit einem bereits vorhandenen System zu kombinieren: d.h. der Faktor Dateistruktur kann vom Entwickler nicht selbst geändert werden.
System- und Abnahmetests ist der kritischste Teil bei einem Softwareprojekt. Ein System, das solch einen Test nicht besteht, kann die Anforderungen des Kunden nicht erfüllen. Sollte es einem Fehler gelingen auch diese Stufe zu überspringen, hat dies mit sehr großer Wahrscheinlichkeit große Auswirkungen auf die Kosten der Entwicklung.
Dies hat drei Gründe:
1. Der Fehler erfordert einen riesigen Aufwand der Respezifikation, des Redesigns und des Reprogrammierens, um diesen Fehler wieder auszubessern.
2. Wenn ein Test fehlgeschlagen ist, könnte der Kunde darauf bestehen auch andere Tests wiederholen zu lassen. Der Grund für die Testwiederholung liegt darin, ein falsches Ergebnis könnte die in der Hierarchie darunterliegenden Funktionen beeinflußt haben.
3. Danach muß noch mal geklärt werden, ob nicht andere Fehler übersehen worden sind.
Man kann sich ungefähr ausmalen wieviele Tests dies bei einem großen Projekt sein könnten (Tausende Tests).
Als Folge eines Fehlers, muß man den gesamten Testvorgang neu starten.
Für manche mag es danach aussehen, daß in diesem Stadium es äußerst früh ist um mit dem Testen zu beginnen.
Es gibt jedoch eine Menge guter Gründe dafür:
Warum so früh testen ?
1. Ein Grund wurde schon genannt. Wenn man für dieses System einige spezielle Hardwaremittel braucht, diese aber erst bestellen muß, hätte man eine Standzeit, die aber Geld kostet.
2. Ein Softwareprojekt entsteht nicht in Isolation. Falls der Entwickler eine kleinere Firma ist, gibt es eine Reihe von anderen Projekten die gleichzeitig ablaufen. Die Aufwandschätzung für solch ein Softwareprojekt kann ein sehr komplizierter Prozeß werden und ist keine beneidenswerte Arbeit des Managers. Es ist notwendig, so früh wie möglich eine möglichst genaue Aufwandschätzung durchzuführen.
3. Für viele Projekte ist der Abnahmetest zusammen mit der Systemspezifikation, die vertraglichen Dokumente. Manche Kunden ziehen es vor, einen Abnahmetest zu lesen, als eine Systemspezifikation, mit dem Vorteil, daß sie sich einen Überblick verschaffen, was das System tun wird können. Dieses Vertragsdokument sollte so früh wie möglich erstellt werden.
Die Entwicklung des Systems und Abnahmetests geschehen im gesamtem Softwareprojekt. Man gibt, entweder kurz danach oder während der Spezifikationsphase, die genauen Testergebnisse aus.
Der Entwickler hat zwei Typen von Tests vorzubereiten:
- Systemtests
- Abnahmetests
Diese Tests sind sich sehr ähnlich. Jedoch ist ihr kleiner Unterschied sehr entscheidend.
Der Systemtest wird mit den Umgebungsbedingungen des Entwicklers durchgeführt, während der Abnahmetest in dem System gemacht wird, indem es laufen soll. Beim Abnahmetest wird automatisch der Kunde mit einbezogen, der als Zeuge fungieren soll, und außerdem muß er die abgeschlossenen Testdokumente signieren. Der Entwickler wählt Sets von Systemtests aus und daraus entwickelt er Subsets für die Abnahmetests. Der Kunde ist jedoch nur an Tests interessiert, die das externe Verhalten des Systems ausgeben.
Pflichtenheft (customer statement of requirements): Wird vom Kunden alleine erstellt.
Spezifikation wird vom Kunden und vom Systemanalytiker gemeinsam in Benutzersprache verfaßt.
In der Spezifikation enthalten:
- Funktionen des Systems - DfD, Dekomposition
- Randbedingungen - Zeit- (für Suche 0,4 sec) und Speicherverbrauch (Programm < 2 MB)
- Benutzeroberfläche (Liste aller Masken)
- Schnittstelle zu anderen Systemen
In der Spezifikation nicht enthalten:
- Banalitäten = Platitüden = bla bla bla
- Mehrdeutigkeiten wie "meistens ", "verarbeiten " und "normalerweise "
- Implementierungs-, und Entwurfsanweisungen (z.B.: in C++ geschrieben)
Allgemeine Eigenschaften:
- die Spezifikation muß eindeutig sein
- immer Status anzeigen
- viele Bilder
- Masken
- Übergangsgraphiken
- Prüfungen für Inkonsistenzen
Ein Windows-Entwickler kann bis ins Detail das Verhalten und Aussehen seiner Anwendungen selber festlegen. Ihm steht die ganze Leistungsfähigkeit des Systems zur Verfügung, um blendende, elegante und vorallem nützliche Anwendungen zu schaffen.
Bevor ich einige brauchbare Methoden für den Entwurf der Programmoberfläche vorstelle, möchte ich an einigen abschreckenden Beispielen zeigen, wie man es besser nicht tut.
Folie 1
Folie 1 zeigt die Maske, die zur Datenerfassung einer Versicherung dient. Die Augen finden keinen Ruhepunkt, die Anordnung ist einfach undurchschaubar; eine Ausrichtung ist praktisch nicht vorhanden.
· Welche Daten gehören zusammen ?
· Sind irgendwelche Bedienelemente von einem Anderen abhängig ?
· Welches Feld ist das Wichtigste ?
· Lassen sich die Zahlen in der unteren Reihe bearbeiten ?
· Was bedeuten sie überhaupt ?
Folie 2
Folie 2 sieht nicht gerade besonders gut aus, denn die Reihenfolge der Arbeitsgänge ist schlechter. Die Maske zeigt an, ob ein bestimmter Versicherungsschutz für den Versicherten vorliegt.
Das statische Textfeld am unteren Rand gibt völlig überflüssige Anweisungen, denn nirgends läßt sich die Auswahl "NEW APPLICATION" oder "UPDATE APPLICATION" treffen.
Folie 3
In Folie 3 legte der Entwickler großen Wert auf die Ausrichtung der Bedienelemente. Bei uns ist es üblich, von links nach rechts, und von oben nach unten zu lesen. In dieser Maske muß der Anwender die Felder rechts ausfüllen und dann zur linken Seite wechseln, um die gewünschte Aktion durchzuführen.
Außerdem sind die Eingabefelder alle gleich lang, obwohl schon der erste Blick genügt, um festzustellen, daß die typischen Eingaben in die jeweiligen Felder unterschiedlich lang sein werden.
Folie 4
Der Entwickler der Eingabemaske in Folie 4 hat eine Vorliebe für verschachtelte Menüs. Wenn es tatsächlich so viele Menüoptionen geben muß, so ist es besser, sie in einem Dialog anzubieten.
Es ist natürlich auch nicht besser so zu gestalten, wie es Folie 5 zeigt.
Folie 5
Diese Folie ertrinkt fast in Optionsschaltflächen. Sicher ist es hier besser, ein Pull-Down-Menü zu verwenden (Listbox oder Combobox).
Folie 6
Folie 6 ist ein weiteres Beispiel für rivalisierende Schaltflächen. Was ist der Unterschied zwischen APPLY und ACCEPT ? Da mit APPLY keine sichtbare Anderungen verbunden sind, ist diese Schaltfläche sowieso überflüssig.
Wichtig ist es, daß sich die Programmierer nicht nur mit dem Codieren befassen, sondern auch mit dem Layout. Sogar bei erfahrenen Entwicklern ist dieses Problem schon aufgetreten. Sie haben mit bestimmten Anforderungen an das Projekt angefangen, einer groben Spezifikation, aber sich kaum mit dem Auftraggeber über die Gestaltung der verschiedenen Masken (dem Layout) auseinandergesetzt. Sobald die ersten Probleme bezüglich Maske auftauchen, stellen die Entwickler fest, daß einige dieser Probleme ihre Ursache in der Programmstruktur haben. Ihre Behebung würde nicht nur Anderungen in der Programmstruktur nach sich ziehen, sondern auch in anderen Bereichen (Datenbankstruktur); sie müßten möglicherweise fast von vorne wieder beginnen. Der Ausdruck "QUICK AND DIRTY" ist oft nicht fehl am Platz. Der Entwickler soll sich wirklich Zeit für die Gestaltung der Masken nehmen.
Spätestens hier ergibt sich die Frage "Wer ist mein Kunde" ? Wenn man eine Anwendung innerhalb einer Firma entwickeln soll (Bsp.: XESAS), so muß man den direkten Kontakt zum Anwender suchen. Nur so kann der Anwender wirklich das haben, was er will. Mit dem Anwender die grobe Spezifikation zu besprechen ist sicher sinnvoll. Wenn die Spezifikation dem Anwender zusagt, so beginnt der Prozeß des Prototypings. Der fertige Prototyp wird dann von einigen ausgewählten, nicht eingewiesenen Anwendern getestet. Auch hier können noch nicht umständliche Anderungen vorgenommen werden. Die Entwicklung wird dann weitergeführt bis zur ALPHA-Version (eine reine Testversion). Auch andere Entwickler oder Anwender können ihre graphischen Vorstellungen einbringen.
Weiters stellt sich die Frage "Kennt sich der Anwender mit PC-Programmen aus" ? Wenn man Anwendungen für Neulinge entwickelt, darf man nicht vergessen diverse Hilfe-Funktionen zu berücksichtigen. Am besten konzentriert man sich darauf, daß die Anwenderschnittstelle so gestaltet ist, daß Sie diese am liebsten gar nicht weitergeben möchten.
Es ist auch nicht unwesentlich, wie intensiv die Anwendung benutzt wird. Wenn man den ganzen Tag damit beschäftigt ist, treten die kleinsten Entwurfsschwächen schnell zu Argernissen auf. Wenn man sich nicht so intensiv damit beschäftigt, soll man dem nicht so kritisch beiwohnen.
Sobald die Hauptziele der Anwendung festgelegt sind, ist es essentiell die Arbeitsabläufe zu fixieren. Vielleicht kann man ähnliche Arbeitsabläufe verwenden. Möglicherweise kann man manuelle Vorgänge automatisieren und somit Zeit und Geld sparen.
Sich die genaue Reihenfolge der Funktionen zu überlegen ist ebenfalls wichtig. Man hat ja schließlich nicht vor, dem Anwender überflüssige Programmzustände aufzuzwingen.
Die Amerikaner kennen das Schlagwort KISS - Keep It Simple, Stupid. Eine bessere Interpretation wäre Keep It Simple and Straightforward, also "einfach und zielsicher". Sobald man weiß, welche Datenfelder und Verzweigungen man in der Anwendung braucht, sollte man überprüfen, was wirklich notwendig ist. Beschriftungen, statische Texte, Kontrollfelder, Gruppenrahmen und Optionsschaltflächen verstellen häufig den Blick auf die wirklich wichtigen Teile einer Eingabemaske und verbrauchen doppelt so viel Platz wie Nutzdaten.
Mit 2 einfachen Tricks erhöht man die Übersicht der Masken, nämlich:
· durch eine überlegte Ausrichtung der Bedienelemente in den Masken
· durch die Einheitlichkeit des Maskenaufbaus in der gesamten Anwendung.
Texte richten sich im allgemeinen nach dem linken Rand, bis auf die zentrierten Meldungen in den Meldungsfenstern, und Zahlen werden nach dem rechten Rand ausgerichtet.
Zu dem einheitlichen Erscheinungsbild der Masken gehört die gleiche Größe und Anordnung der Bedienelemente und der Beschriftung, gleiches Verhalten und gleicher Stil. Es ist nicht effizient eine Befehlsschaltfläche in der ersten Maske riesengroß und gleich in der nächsten Maske diese zu klein zu gestalten. Wenn man mittels PUSH-BUTTON eine weitere Maske öffnen kann, so soll diese Maske den selben Namen wie der PUSH-BUTTON haben. Wenn sich bestimmte Datenfelder in mehreren Masken wiederholen, wäre es sinnvoll, diese immer an der gleichen Stelle zu positionieren.
Um all diese Kriterien zu erfüllen gibt es einige grundlegende Dinge für einen einfachen Entwurf:
· Anordnung der Daten in funktionalen Gruppen. Alle Informationen, die der Anwender zur Abwicklung eines bestimmten Vorganges benötigt, gehören in dieselbe Maske.
· Anordnung der Felder, die am häufigsten benutzt werden, sodaß man sie gleich sieht.
· Zusammenfassung der zusammengehörigen Felder in Unterguppen.
· Gleichmäßige Abstände zu den verschiedenen Feldern.
Sobald man die Funktion der Anwendung festgelegt hat, geht es um die Frage, wie viele Fenster man dem Anwender präsentiert. Alle Windows-Anwendungen öffnen zuerst ein Hauptfenster, von dem aus Teilaufgaben in MDI-Fenster oder Dialogfenster abgewickelt werden. Es ist essentiell MDI-Fenster zu benutzen, wenn man in der selben Ebene mehrere Vorgänge abwickeln möchte (Bsp.: Datentausch zwischen Dokumenten). MDI-Fenster sind auch in ihrer Größe beeinflußbar.
Dialogfenster haben normalerweise eine feste Größe und eignen sich somit auf Felder mit festgelegten Datenmengen.
Die Anwenderschnittstelle bildet den Ausgangspunkt für jede Aktion, die ein Anwender durchführen kann. Die Windows-Anwendung erhält die Befehle des Anwenders über:
· Menüs
· Befehlsschaltflächen
· Symbole
· OLE-Verbindungen (Object Linking and Embedding)
Die Funktionsschaltflächen sind von Programm zu Programm verschieden. In Word und Excel sind dies beispielsweise Befehlsschaltflächen mit denen Programmfunktionen angeboten werden; die aber auch über Menüs angesprochen werden können. Der Anwender kann seinen bevorzugten Zugriff individuell auswählen.
Die Anordnung der Menüs und Menüunterpunkte will sorgfältig überlegt sein. Die ersten Gedanken darüber hat man sicher schon in der Spezifikation gemacht; hier ist es aber höchste Zeit die genauen Menüoptionen festzulegen. Anschließend faßt man dann ähnliche Menüpunkte in Gruppen zusammen.
Die Anordnung der anderen Menüpunkte hängt von einer Reihe von verschiedenen Faktoren ab:
· von der Häufigkeit der Benutzung
· von der Wichtigkeit
· von den Arbeitsabläufen
· von der Reihenfolge
Folie 7
Folie7 zeigt ein etwas verwirrendes Menü; und die verbesserte Version. Das Sprichwort "Weniger ist oft mehr" oder "In der Kürze liegt die Würze" trifft hier voll zu.
Einige typische Bedienungsfehler lassen sich schon durch die Gestaltung der Masken vermeiden:
· Alle Menüpunkte, deren Auswahl zu Schäden führen könnte, zu sperren, ist sicher wichtig.
· Der Griff zu Auswahllisten ist sicher der richtige. Den Benutzer sooft als möglich auswählen zu lassen, verhindert unnötige Schreibfehler.
· Vor jeder kritischen Situation den Anwender noch einmal bestätigen lassen (Bsp.: Hiermit beenden Sie Ihre Windows-Sitzung).
Folie 8
Folie 8 ist ein Beispiel für feldspezifische Datenvalidierung. Die Anwendung zeigt sofort eine Fehlermeldung an, wenn der Anwender eine ungültige Staatenabkürzung eingibt und mit dem Cursor das nächste Feld anklickt.
Wenn der Anwender ein Feld anklickt, das er nicht bearbeiten darf, genügt ein simples Pieps als Hinweis.
Einheitlichkeit ist der Schlüssel für den effektiven Einsatz von Schriftarten und Farben. Falls die Systemschrift zu langweilig oder zu häßlich erscheint, kann man ohneweiters auf eine andere Schriftart ausweichen. Diese sollte aber leicht lesbar und nicht zu klein bzw. zu groß sein. Alles in Großbuchstaben zu schreiben ist nicht effizient, da man dies nicht so gut und auf den ersten Blick lesen kann. Eine Ausnahme wäre beispielsweise die OK-Taste.
Um die Aufmerksamkeit des Anwenders auf sich zu lenken, sollten ebenfalls verschiedene Farben für die Maskengestaltung herangezogen werden. Die Farben sind aber eher sanft und nicht grell zu wählen.
Farben können auch als Informationsträger verwendet werden. Beispielsweise macht man gesperrte Felder grün und die fehlerhinweisenden Felder rot.
- Einheitlichkeit, Richtlinien (Kontrolle)
- Ergonomie (Arbeitsrichtung von links nach rechts und von oben nach unten)
- natürliche Reihenfolge
- an bestehende schriftliche Formulare halten
- Farben: auf großer Fläche keine grellen Farben und nicht zu viele Farben
- Felder: Muß-, Kann- und berechnete Felder in anderen Farben
- Schriften: nicht mehr als zwei verschiedene
- Gruppierung
- nicht zu viele Steuerelemente
- PB sollten am Aussehen von Formularen etwas ändern (Checkbox)
- Bilder für PB
- Unterscheidung: aktiv - inaktiv
- Probleme: Formulare mit zuwenig Platz
- Funktionen: Menü, PB oder Hotkeys
- Hilfe, Statuszeilen, Warnton
- Defaults
- einheitliche Benennung
- Qualifikation des Anwenders beachten
Das Datenflußdiagramm zeigt die Prozesse und den Fluß der Daten durch diese Prozesse.
Es gibt verschiedene Möglichkeiten es einzusetzen, von schwierigen Geschäftsbeziehungen bishin zu Softwareprogrammabläufen oder gar nur einzelner Unterprogramme.
Man bezeichnet ein Datenflußdiagramm auch als erste Stufe eines strukturierten Softwaredesigns, da es den gesamten Datenfluß durch das System bzw. Programm zeigt.
Es ist in erster Linie ein System-Analyse-Werkzeug, welches man für die Darstellung der Grundbestandteile und den Datenfluß durch diese benötigt.
Bestandteile eines Datenflußdiagramm (4 Grundkomponenten):
1) Datenfluß:
Pfeil mit Name darüber, zeigt den Datenfluß durch das System
2) Prozeß:
Abgerundetes Rechteck mit Namen des Prozesses (sprechender Name!)
Keine andere Information über den Prozeß in Datenflußdiagramm
3) Data Store:
Name zwischen zwei waagrechten Strichen, repräsentiert ein lokales File in das entweder Daten eingelesen werden, oder von dem Daten gelesen werden.
4) Terminator:
Rechteck mit Namen, gibt die Herkunft (Source) bzw. den Empfänger (Sink) der Daten an. Doch sie werden meistens nicht in die Datenflußdiagramme eingezeichnet.
Auf der Folie sehen wir ein Beispiel eines Datenflußdiagrammes für den Ablauf einer Kundenbestellung.
Zur Folie:
Wenn ein Auftrag einlangt, wird der Kunde überprüft (Existenz, Kontostand, ).
Nun werden alle Produkte auf der Bestellung überprüft, ob sie verfügbar oder lieferbar sind. Treten hier Unzulänglichkeiten auf, wird ein Lieferrückstand erzeugt. Schlußendlich wird eine Bestellung erzeugt und der Kundenauftrag mit dem Lieferdatum versehen.
Ein Datenflußdiagramm zeigt den Datenfluß in einem konkreten Prozeß, der wieder aus mehreren Unterprozessen besteht, die man wieder in eigene Datenflußdiagramme zerlegen kann.
So kann man ein System bis in die tiefsten Ebenen zerlegen. Also ein Datenflußdiagramm gibt uns keine Detaile über den Datenfluß in den Unterprozessen die nur als abgerundetes Kästchen dargestellt werden, doch dies kann man wieder zerlegen und so mehr über den Datenfluß erfahren.
Aber wie genau soll man ein System zersplitten?
Man soll so weit zersplitten, bis ein Prozeß durch Worte auf einer Seite vollständig beschrieben werden kann, ohne das Informationen verloren gehen.
Auch in einem Datenflußdiagramm sollte man Einschränkungen treffen, es sollten nie mehr als 12 Prozesse dargestellt werden, da es sehr schwer zu lesen wird und die gewünschte Übersichtlichkeit verloren geht. Die ideale Anzahl wären 6-7 Prozesse.
Wenn ein Datenflußdiagramm während der Strukturanalyse entwickelt wird, entwickelt man auch eine Prozeßspezifikation um zusätzliche Information über das System unterzubringen.
Sie definiert wie die Daten in und aus dem Prozeß fließen und was für Operationen mit ihnen durchgeführt werden.
Eine Variante ist eine Aktionsliste, die ähnlich einem Programm aufgebaut ist.
Data dictionary AUSLASSEN
Gane and Sarson AUSLASSEN
Ein Datenflußdiagramm ist ein sehr wertvolles Werkzeug für die Prüfung des Dokumenten- bzw. Datenflusses in komplizierten Systemen. Es gibt jedoch auch viele Fälle, wo ein Datenflußdiagramm falsch eingesetzt wird bzw. immer wieder Fehler auftreten, besonders bei Querverbindungen (Cross-Checking), da der Input und der Output eines Datenflußdiagrammes oft inkonsistent ist. Und ist das Programm einmal geschrieben, so ist es sehr umständlich, die Fehler auszubessern. Doch heute gibt es schon die Möglichkeit ein Datenflußdiagramm mit dem Computer zu erstellen, der das System auf Inkonsistenz überprüft.
Im Gegensatz zum Datenflußdiagramm hat man beim Control Flow Model die Möglichkeit den Datenfluß ereignisorientiert zu gestalten.
Ereignisse sind wie Boolean Variablen (true or false), oder ein konkretes Ereignis (leer, verstopft, voll).
Funktionale Dekomposition ist eine Strategie, Probleme in Unterprobleme (Sub-Components) zu zerstreuen. Diese Unterprobleme werden wieder in Unterprobleme, also in Unter-Unterprobleme (Sub-Sub-Components), zerlegt. Dies wird solange fortgesetzt bis das unterste Level der Detailierung erreicht wurde.
Konkretes Beispiel:
Lies eine Serie von Spannungen ein und bilde das Maximum, Minimum und den Durchschnitt.
Da die ersten zwei Punkte schon auf der niedrigsten Stufe sind, können sie nicht mehr in noch einfachere Bestandteile zerlegt werden.
Somit kann man nur mehr den Durchschnittswert noch weiter zerlegen.
Das ergibt folgendes Design:
einlesen einer Serie von Spannungen
errechne das Max
errechne das Min
errechne die Summe
dividiere die Summe durch die Zahl der eingelesenen Spannungen.
Am Ende werden die einzelnen Teillösungen der Teilprobleme wieder zu einem Gesamtproblem und somit auch zu einer Gesamtlösung zusammen gefügt.
Beispiel:
Dies soll die Beziehung zwischen ERD, CDUR-Matrix, Funktionale Dekomposition und
dem Datenflußdiagramm zeigen.
|
Datenseite |
Prozeßseite |
|
mit welchen Daten |
was macht man mit den Daten |
|
ERD (Entity-Relationship-Diagramm) |
DfD (Datenflußdiagramm) Dekomposition |
Das Unternehmen der Zukunft wird zu einem großen Teil mit Hilfe von Computern geführt werden. PCs und Workstations werden die Nervenenden eines unternehmensweiten Netzwerkes sein, das sie mit Großrechnern und den Datenbanken verbindet, die sie benötigen. Einen Großteil des Rechnereinsatzes werden entscheidungsfördernde Operationen (decision-support operations) von unabhängigen Angestellten an ihren vernetzten Workstations ausmachen.
In dieser Umgebung ist Kompatibilität eine Grundvoraussetzung. Nicht nur Hardwarekompatibilität wie z.B. Netzwerk, Plattenlaufwerke oder Drucker, sondern auch Softwarekompatibilität wie z.B. Software-Kooperation von Workstation-Abteilungsrechner-Großrechner, wird von entscheidender Wichtigkeit sein. Besonders wichtig ist auch ein kompatibler Daten-Gebrauch, er muß für Mehrfach-Zugriff geeignet sein, verfügbar in leicht benutzbaren Daten-Modellen sein, und mit geeigneten Werkzeugen bedient werden.
Für Benutzer wird es selbstverständlich sein mit Computern zu arbeiten. Ihnen zur Seite werden eigene DV Abteilungen stehen, die sie beraten und ihnen die geeigneten Werkzeuge zur Verfügung stellen. Endbenutzer werden nicht sehr viel programmieren, und wenn doch, dann entweder in 4. Generationssprachen oder mit easy-to-use-end-user Sprachen.
Kommunikation ist in dieser Umgebung von essentieller Bedeutung. Benutzer wollen nicht Daten erstellen, die es schon auf anderen Computern gibt. Benutzer wollen mit anderen kommunizieren und Daten versenden, genauso wie das auch die Software will (man denke nur an zentrale Datenbanken).
Professionelle DV greift oft auf die selben Datenbanken zurück. Es ist also wünschenswert, rasch und einfach zu Ergebnissen zu gelangen. Noch wichtiger ist es jedoch, möglichst schnell Systeme wieder ändern zu können. Dies setzt wiederum eine saubere und strukturierte Verwendung von Applikations-Generatoren und 4GL Sprachen voraus.
Das Wesentliche von IE bezieht sich auf ein integriertes Set von Methoden, um eine Umgebung wie oben zu erschaffen und sich darin zu bewegen. Es basiert auf voll normalisierten Daten-Modellen die die Daten eines ganzen Unternehmens beinhalten. Diese Daten werden auf Computern abgelegt und Workstations werden spezielle Werkzeuge benutzen, um Applikationen zu schreiben, die diese Daten benutzen. Diese Werkzeuge werden hochautomatisiert sein, geeignet, schnell und einfach Applikationen zu erstellen und diese wieder zu verändern.
Wo hingegen sich die meisten strukturierten Techniken auf ein System beziehen, verwendet IE solche strukturierten Techniken für ein ganzes Unternehmen. IE erzeugt Daten-, und Prozeßmodelle für ein ganzes Unternehmen, sodaß Systeme, die von mehreren Teams erstellt wurden, zu einem großen zusammengefaßt werden können.
IE bezieht sich auf das Gegenteil von Software Engineering. Das Hauptaugenmerk von SE bezieht sich auf die Logik von Prozessen; Das Hauptaugenmerk von IE bezieht sich auf die Daten, die davor liegen und die Informationen, die daraus bezogen werden können. IE muß sich auch mit strukturierter Analyse und Code befassen, aber hauptsächlich befaßt sie sich mit nichtprozeduralen Sprachen, Spezifikations Sprachen, Applikations Generatoren und Grafik CAD.
Die Hauptvoraussetzung von IE ist, daß die Daten im Mittelpunkt der DV liegen. Verschiedenste Computer und Prozeduren greifen auf diese Daten zu, um sie zu ändern, erstellen oder zu löschen. Es spielt keine Rolle, von wo oder wie auf die Daten zugegriffen werden kann. Im Zentrum liegen also die Daten ungeschützter Weise. Diese Daten werden von einer Daten-System-Software umgeben, um sie zu schützen und nicht erlaubte Zugriffe abzufangen (ðAuditors).
Die zweite Hauptvoraussetzung von IE ist, daß sich, wie schon erwähnt, die Datentypen in einem Unternehmen nicht wesentlich ändern. Die entity types verändern sich nicht, es sei denn, neue werden hinzugefügt. Die attributes verändern sich ebenfalls kaum. Die Daten ändern sich also konstant gleich, wie z.B. auf einem Fluginfo-Brett auf dem Flughafen, aber die Struktur bleibt bei einem gutem Entwurf gleich.
Daten-Administratoren verwenden nun saubere automatisierte strukturierte Techniken, um diese Daten-Modelle zu erstellen. Wenn diese Daten-Modelle gut erstellt wurden, ändern sie sich wenig bis garnicht und bilden eine gute Basis, auf die die Prozeduren aufsetzen können.
Jetzt, wo die Daten relativ stabil sind, können die Prozeduren, die diese Daten verwenden, leicht und schnell ausgetauscht werden. Dies ist ein sehr wichtiger Aspekt des IE.
Die Prozeduren, Hardware, Software, Netzwerke, , mögen sich ja sehr schnell ändern, für die Daten ist das jedoch egal. Daten bleiben nur verfügbar und sichtbar, wenn eine Daten- Infrastruktur geschaffen und sie korrekt identifiziert wurde. Erst dann wird eine maximale Flexibilität verfügbar.
Bei den Prozeduren werden datenorientierte Techniken gegenüber den prozedurorientierten Techniken bevorzugt. Daraus ergeben sich eine schnell zu ändernde Umgebung und Prozeduren.
Auch bei den Kosten spricht viel für IE. Konnten bisher Anderungen nur schwer vorgenommen werden, so ist das beim IE sehr leicht (einfach Prozeduren umschreiben). Auch die Wartungskosten fallen viel geringer aus.
In einem Satz:
Mit IE kann man Systeme erstellen, die sehr schnell modifiziert werden können. Prozeduren werden einfach implementiert, wenn sie gebraucht werden.
IE stellt ein ineinandergreifendes Set von Methoden dar. Diese können einfach als Blöcke dargestellt werden. Jeder Block hängt von seinem unteren ab.
Der erste Block bezieht sich auf die strategische Planung. Hier wird die Hierarchie eines Unternehmens festgestellt. Auch die Ziele werden in dieser Ebene festgelegt, und die dazu erforderlichen Informationen bestimmt.
Der nächste Block erstellt eine Übersicht über die Daten, die das Unternehmen benötigt. Dies wird auch Top-Down Analyse genannt, denn hierbei wird festgelegt, welche Daten gespeichert werden müssen und welche Daten in Beziehung zu anderen stehen.
Der dritte Block bezieht sich auf die Daten-Modellierung (data modelling). Informations-Analytiker legen die Typen (types) fest. Diese wiederum erstellen ein Informations-Modell, welches eine Übersicht, jedoch nicht alle Details, zeigt. Erst bei der Daten-Modellierung werden alle Details festgelegt. Es entsteht eine logische Datenbank. Es gilt jetzt, sie möglichst stabil zu machen.
Ein wichtiger Aspekt ist, daß die Daten in einer organisierten, strukturierten und von der Verwendung unabhängigen Form existieren.
Es wird auch nur eine stabile Datenbank entstehen, wenn wir die Daten nach ihren eigenen Eigenschaften strukturieren und diese Eigenschaften nicht verändern. Dies erspart in Zukunft eine Menge Arbeit, weil die Programme dadurch weniger spezifisch werden. Man kann sich das wie eine Fabrik, die nur eine Sorte Fisch verarbeiten kann vorstellen. Man sollte auch hier den Fischen keine Nummer aufdrucken, sondern lieber zB Größe-Art-Gewicht verwenden.
In diesem Block wird auch erstmals gesplittet. D.h. das Unternehmen wird genauer und einzelner betrachtet (z.B.: Abteilungen). Es werden Teilgruppen gebildet. Lokale Daten Modelle werden erstellt.
Da in letzter Zeit vermehrt End-User Sprachen verwendet werden, müssen sie auch hier integriert werden. Dies geschieht in Block 4 und 5. Es gilt zu verhindern, daß Benutzer unnötig neue Strukturen erstellen. Dies erfordert eine sorgfältige Implementierung.
In manchen Fällen ist es notwendig, Daten zu erstellen, die nicht voll normalisiert sind, und auch nicht genau in Daten-Modellen vorhanden sind, deshalb sitzt Block 4 auf Block 2.
Block 6 und die Blöcke darüber basieren auf der Arbeit von System-Analytikern. Block 6 bezieht sich immer auf die Analyse eines Teils des Unternehmens. Die Funktion eines solchen Bereiches wird in Prozesse aufgespaltet. Es werden ein Abhängigkeits-Diagramm und ein Datenflußdiagramm erstellt.
Bei diesem Prozeß wird auch gleichzeitig das Daten-Modell überprüft, da sämtliche entity types benötigt werden. Fehlt einer, so kann man ihn hier noch erstellen.
Eine Matrix zeigt hier die Zusammenhänge.
Block 7 bezieht sich nur auf die Erstellung von Prozeduren. Ereignisdiagramme erklären jede Prozedur. Entscheidungsbäume oder -tabellen werden erstellt, wo diese notwendig sind.
Ereignisdiagramme können auch direkt von korrekt erstellten Abhängigkeits- und Daten-Navigationsdiagrammen erstellt werden. Bei dieser Arbeit wird der Programmierer von automatischen CAD unterstützt.
Die Verwendung von Ereignisdiagrammen wird auch notwendig, wenn die Prozeduren in verschiedenen Sprachen geschrieben werden sollen (ðPortierbarkeit).
Auch werden hier die Feinheiten der Daten sichtbar. Es wird hier eine sehr starke Hilfe vom Benutzer gefordert. Der Analytiker versteht die Daten nicht, der Benutzer schon. Erst wenn beide zusammenarbeiten, kann eine funktionierende Datenbank entstehen und Mißverständnisse geklärt werden.
Auch weiß der Analytiker nicht, welche Daten für den Benutzer wichtig sind. Der Benutzer muß versuchen, seinen Entscheidungsfindungsprozeß zu erklären. Nur so kann der Analytiker feststellen, welche Informationen er dem Benutzer zu Verfügung stellen muß.
Für den Benutzer selbst spielen neue Werkzeuge eine wichtige Rolle. Um noch mehr Flexibilität zu erhalten, kann er z.B. 4GL verwenden. Dies verkürzt auch die Zeiten, die eine umständliche Programmierung erfordern würde.
Es ist sehr verführerisch, eine Datenbank ohne die Fundamente wie Block 1-3 zu machen. Doch in Unternehmen werden oft Daten mehrfach, gleichzeitig, , benutzt. Wenn nur ein einzelner mit diesen Daten zu tun hat und diese wartet, ist das unproblematisch, doch bei nur ein bißchen größeren Dingen kann dies kritisch werden.
Strategisches Daten-Planen ist eine erprobte Methode, die nicht viel kostet, wenn man es mit den versteckten Kosten von chaotischen Daten vergleicht.
So ist moderne DV ohne die Blöcken 1-3 wie ein Haus auf Sand. Früher oder später muß es abgerissen und neu gebaut werden.
· Lifecycle
° Datenseite
° Prozeßseite
· Prototyping
· Information Engineering
Es sollten unternehmensweite Datenbanksysteme verwendet werden. Z.B.:
· kein Pflichtenheft (Unternehmen kommt zu Entwickler).
· statt des Information System Planning
· das ganze Unternehmen wird betrachtet
Die Jackson Methode ist eine Top-down Entwurfsmethode.
Die Top-down Methode sorgt für:
· Genau-spezifizierte (angegebene) Entwurfsprozeßschritte
· Verwendung von graph. Diagrammen
· Methoden zur Bewertung der Richtigkeit eines Entwurfes
Die Jackson Methode:
· basiert auf die Analyse von Datenstrukturen, d.h. sie ist datenorientiert
· ist eine datengelenkte Programmentwurfsmethode
· zeigt ein Programm als sequentielles (aufeinanderfolgendes) Verfahren
· zeigt INPUT und OUTPUT als sequentielle Ströme
Die prinzipielle Methode des Jackson teilt sich allg. in 4 Schritte:
1. DATENSCHRITT
2. PROGRAMMSCHRITT
3. OPERATIONSSCHRITT
4. TEXTSCHRITT
Jackson verfügt über 3 verschiedene Anwendungstechniken:
BEISPIEL: Eignungsprogramm für Arbeiter
Der Zweck dieses Programmes soll die Zusammenfassung von Arbeitereignungen für jede Abteilung in einen Betrieb, wobei die Abteilungen geordnet sein sollten. Wir wollen dies in einer einfachen Liste mit einem Kopf und keinen Seitennummern.
Es soll lediglich so aussehen:
ABTEILUNG EIGNUNG ARBEITER#
01 fräsen 06
01 schweißen 03
02 konstruieren 01
. . .
. . .
Der INPUT für dieses Programm soll das ARBEITER-FILE sein, welches Aufzeichnungen von Eignungsnummern und Abteilungsnummern beinhaltet.
Diese Skizze zeigt ein Netzwerksystem-Diagramm für das ARBEITEREIGNUNGSSYSTEM. Es zeigt, daß dieses System zusammengesetzt ist aus :
- 1 Programm : ARB.EIG.PROGRAMM und
- 2 Datenströme : EIGNUNGSFILE und EIGNUNGSREPORT
1.Schritt: DATENSCHRITT
Es wird nun jeder Datenstrom als hierachische Struktur dargestellt, dazu wird eine Baumstruktur verwendet.
Die Skizze - unten bei Programmschritt - zeigt das Baumstrukturdiagramm für die Input- und Outputdatenströme. Der Zweck der Baumstruktur soll die Reihenfolge zeigen, in der die Datenrecords auf das Programm Zutritt haben. Das heißt, es is unbedingt notwendig alle Datenströme vollständig und richtig in der Baumstruktur darzustellen.
2.Schritt: PROGRAMMSCHRITT
Nun erfolgt das Verbinden der Datenstrukturen zu einer Programmstruktur.
Der Programmschritt enthält folgende 2.Schritte:
1.a. Alle Übereinstimmungen zwischen den Komponenten der Datenstrukturen sind durch forschen (studieren) der Datenströme und der Problemspezifikation erkenntlich zu machen. Die
Skizze - unten - zeigt, daß durch die fetten Pfeile das EIGNUNGSFILE im Inputbaum dem EIGNUNGSREPORT des Outputbaumes entspricht. Das heißt, wenn das ARBEITEREIGNUNGSPROGRAMM ausgeführt ist, dann wird der Outputdatenstrom
(= EIGNUNGSREPORT) vom Inputdatenstrom (= EIGNUNGSFILE) erzeugt. Dadurch ist eine 1:1 Übereinstimmung zwischen den 2 Datenströmen vorhanden. Jackson ordnet sich bei dieser 1:1 Beziehung als eine consume-produce relationship (fette Pfeile) ein.
1.b. -Skizze a- zeigt die Programmstruktur des eigentlichen Programmmes (ARB:EIGN:PROGR.) in Form eines Baumstrukturdiagrammes. Dabei werden die gleichen Bezeichnungen wie im Datenstrukturdiagramm verwendet.
Die Bedingung CONSUME oder PRODUCE wird vor jeder Komponentenbezeichnung geschrieben, welche anzeigt, ob die Programmkomponente Inputdaten konsumiert oder Outputdaten produziert.
-Skizze a - -Skizze b-
2. Der 2.Teil der Programmstruktur ist die Prüfung auf Richtigkeit. Dies geschieht durch reduzieren der Programmstruktur in eine Komponentendatenstruktur (Skizze b).
- Eliminieren der CONSUME und PRODUCE
- Eliminieren der Programmkomponenten die nicht mehr am Datenstrom teilhaben
- Eliminieren jeder Box die wegfällt (consume)
OPERATIONSCHRITT
Gliedern sich in 3.Schritte:
1. Nun wird eine Liste der programmtechnischen Befehle erstellt. Diese Liste beginnt beim Output und endet beim Input.
2. Jeder Operation wird ein geeigneter Platz in der Programmstruktur zugeteilt.
3. Als letzter wird geprüft, ob alle Outputs produziert werden und alle Inputs konsumiert werden.
TEXTSCHRITT
Im Textschritt wird nun die Struktur in eine Textform umgewandelt , d.h. die Programmstruktur wird ausprogrammiert.
Beurteilung der Jackson Methode
Die Jackson Design Methode ist nur für einfache Programmentwürfe geeignet, da dieser ganze Entwurfsprozeß für einfache Programme übersichtlich und trivial ist. Jackson ist geeignet um kleinere Blöcke für komplexe Programme zu erstellen. Allerdings ist der Entwurf der einfachen Programme oft so trivial, daß der richtige Entwurf durch Lesen der Problembeschreibung den selben Effekt wie die Jackson Methode hat. Ergänzung
vier Schritte:
1. Datenschritt (Input - Output, Datenstruktur)
2. Programmschritt (Erstellen einer Programmstruktur)
3. Operationsschritt (Befehle in Programmstruktur übertragen)
4. Textschritt (Programmierung)
Verfahren zum Entwurf, daß datenorientiert ist.
Es kümmert sich die Datenflüsse an, und kommt dadurch zu einem Ergebnis, aus welchen Teilfunktionen die Funktion des Programmes besteht. Bsp.:
|
Klasse |
Schüler |
Wahlfach |
|
5. HBa |
Mayer |
Fußball |
Nach Klasse geordnet. Fließt so ins Programm. Ergebnis soll sein:
|
Klasse |
Wahlfach |
Anzahl |
|
5. HBa |
Fußball |
4 |
Daraus folgt ein Diagramm mit folgenden Funktionen:
Ein Aufmerksames Lesen der Angabe ersetzt den Jackson. Außerdem werden die Daten nicht mehr von der einen Datei in die andere geschrieben, sondern es gibt Relationale Datenbanken.
T Structure Clash
Programme und Systeme zu designen ist ein Entscheidungsprozeß, der viele technische Entscheidungen miteinbezieht. Das Ziel des strukturierten Designs ist es, ein Verfahren zu sichern, daß dem Designer die Möglichkeit gibt, diese Entscheidungen in/nach einem systematischen Weg zu machen.
Der erste Schritt im strukturiertem Design ist das Designproblem, mittels einem Datenflußdiagramm, durch ein System zu zeigen. Dieses System besteht aus Prozessen, die mit den Daten operieren. Diese Prozesse und die Datenverbindung werden zur Basis, zum Definieren der Programmkomponenten.
Der zweite Schritt im strukturiertem Design ist das Programmdesign in einer Hierarchie von funktionalen Komponenten zu zeigen. Ein Strukturdiagramm dient dazu, um eine Übersicht über das Design zu zeigen. Das Strukturdiagramm ist abgeleitet vom Datenflußdiagramm.
Strukturiertes Design unterstützt zwei Designstrategien zur Umsetzung vom Datenflußdiagramm zum Strukturdiagramm: die Transformanalyse und die Transactionsanalyse.
Transformanalyse:
Transformanalyse ist ein Informationsflußmodell, das gebraucht wird um ein Programm zu designen, das die primären funktionalen Komponenten und die wichtigsten Ein- und Ausgaben für diese Komponenten identifiziert. Das Datenflußdiagramm ist die primäre Eingabe für den Transformanalyseprozeß. (Abb.)
Die Transformanalyse wird in drei Teile unterteilt:
1. Das Datenflußdiagramm wird in drei Teile unterteilt:
- Input
- Output
- Rechenaufgabe
2. Erstellen eines high-level Strukturdiagramms, für jeden Zweig und für jede zentrale Transform ein Modul zeichnen.
3. Alle high-level Module in Unterprogramme umwandeln.
Darstellung des Transformanalyseprozesses
Transactionsanalyse:
Transactionsanalyse ist eine alternative Designstrategie. Eine Transaction (Durchführung) ist jedes Datenelement das eine Aktion auslöst.
Die Transactionsanalyse wird in vier Stufen unterteilt:
1. Identifizieren der Transactionsquellen durch Prüfen der Problembeschreibung.
2. Ausfindigmachen des Transactionszentrums durch Prüfen des Datenflußdiagramms.
3. Identifizieren der Transactionsmodule durch Prüfen des Datenflußdiagrammes und Erstellen eines high-level Strukturdiagramms.
4. Bilden eines kompletten Strukturdiagrammes
Die Aufgabe des dritten Schrittes, der Designbewertung, ist es, die Qualität des Designs, das mittels Transaction- oder Transformanalyse erstellt wurde, zu bewerten. Es gibt viele Arten des Designs für ein Problem, also braucht man einen Weg, um die Qualität objektiv zu messen.
Hierzu gibt es wieder zwei Bewertungstechniken: Kopplung und Kohäsion
Kopplung:
Die Kopplung mißt den Grad der Selbständigkeit der Module. Wenn es eine geringe Interaction (Wechselwirkung) zwischen zwei Modulen gibt, so wird dies 'locker gekoppelt' genannt. Gibt es eine große Wechselwirkung zwischen zwei Modulen, so nennt man dies eine 'enge Kopplung'. Ein hoch qualifiziertes Design ist, wenn die Module so locker wie möglich gekoppelt sind.
Es sind fünf Typen von Kopplung möglich:
- Daten
- stamp
- control
- common
- content
Daten-Kopplung ist der beste und lockerste Typ von Kopplung. Content-Kopplung ist der schlechteste und engste Typ von Kopplung.
Kohäsion:
Die Kohäsion mißt, wie stark die Elemente innerhalb eines Moduls verbunden sind. Je stärker, desto besser. Es gibt sieben Levels die die Kohäsion zeigen:
- Functional
- Sequential
- Communicational
- Procedural
- Temporal
- Logical
- Coincidental
Wobei die funktionale Kohäsion die stärkste und am meisten wünschenswerte Kohäsion ist und die coincidental die Schwächste und Unerwünschteste ist.
Um die Kohäsion und die Kopplung der Module zu messen, muß das Strukturdiagramm geprüft sein. Der Typ der Kopplung wird entschlossen in dem man sich den Datenfluß zwischen Modulen anschaut.
Der letzte Schritt des strukturierten Designs ist es, das Design für die Durchführung vorzubereiten. Das nennt man das Verpacken (Packaging) eines Designs. Verpacken ist ein Prozeß des Teilens des logischen Programmdesigns in eine physikalische Durchführungseinheit. Dies nennt man load unit (Ladeeinheit). Jede load unit wird ins Memory gebracht und als eine Einheit im Betriebssystem ausgeführt. Die Absicht des Verpackens ist es, die physikalischen Systemkomponenten zu definieren, die in einer wirklichen Computerumgebung durchgeführt werden können. Verpacken wird in Schritten ausgeführt. Einige Schritte werden vor dem Design ausgeführt, andere wieder besser am Ende des Designprozesses.
Predesign Packaging:
Am Ende der Analyse, wird das System in jobs und jobsteps verpackt. Ein job ist eine Reihenfolge von einem oder mehreren jobsteps. Ein jobstep ist ein Hauptprogramm und dessen Unterprogramme. Das Datenflußdiagramm ist zu diesem Punkt, durch Bilden dreier Grenzen, verpackt:
1. Hardwaregrenze
2. Batch/on-line/real-time Grenze
3. Operationszyklusgrenze
Postdesign Packaging:
Jeder jobstep, repräsentiert als Datenflußdiagramm, hat die Designphase schon passiert. Während des Designs wird jeder jobstep als Wert eines Strukturdiagramms definiert. Am Ende wird jedes Strukturdiagramm in ausführbare Programme und Ladeeinheiten (load units) verpackt. Die kleinstmögliche Ladeeinheit ist ein Modul, die größtmögliche das ganze Strukurdiagramm.
Softwareentwicklungsphasen:
|
Analyse |
Design |
|
Problem / Anforderung |
Lösung |
|
Dekomposition (Prozeß) |
Structure chart |
|
Datenflußdiagramm / CDUR - Matrix |
Strukturdiagramm |
|
ERD |
ERD |
"Nur dem Fehler dem nachgegangen wird, der kann auch ausgebessert werden." Das ist ein Leitsatz, den sich jedes Qualitätsmanagement zu Herzen nehmen sollte. Da es aber zu viele Dinge gibt, die fehlerhaft sein könnten, und denen nachgegangen werden muß, wäre der Manager vollkommen überfordert. Hier springt dann die Software-Qualitätssicherung ein und hilft dem Manager alle notwendigen Dinge präzise zu überwachen.
Bevor allerdings eine SQS-Organisation gebildet werden kann, muß entschieden werden, wie wichtig Software-Qualität überhaupt für die Organisation ist. Ist sie zum Beispiel wichtiger als der rechtzeitige Lieferzeitpunkt, oder ist es wichtiger doch noch einigen Fehlern auf die Spur zu kommen.
Besonders wichtig ist es, daß das Engagement des Managements bis in die tagtägliche Arbeit reicht, da sonst keine konsequente Verbesserung der Software-Qualität zu erwarten ist.
Der Hauptvorteil eines SQS-Programms ist, daß es dem Management die Sicherheit bietet, daß der offiziell bestehende Prozeß implementiert wird. Jetzt noch einige weitere Punkte, die diese Sicherheit bieten:
- eine angemessene Entwicklungsmethode ist vorhanden
- Die Projektentwickler verwenden Standards und Prozeduren in ihrer Arbeit
- es werden unabhängige Berichte und Prüfungen durchgeführt
- eine Dokumentation wird erstellt
- die Dokumentation wird während und nicht nach der Entwicklung erstellt
- durch Testen werden alle Risiko-Stellen im Produkt hervorgehoben
- erst wenn eine Software-Aufgabe zufriedenstellend beendet wurde, wird mit der nächsten begonnen
- jede Abweichung von Standards und Prozeduren wird sobald als möglich gemeldet
- das Projekt wird von externen Profis geprüft
- usw.
Gründe für die Besorgnis um die Qualität sind eigentlich schon vorprogrammiert. So ist es für jeden doch selbstverständlich, daß der Autopilot in einem Flugzeug korrekt funktioniert, daß unsere Banksysteme laufen, oder daß die Luftraumüberwachung keine Fehler macht.
Außerdem ist es immer hilfreich, wenn man jemanden hat, der genügend Erfahrung auf dem Gebiet SQS hat und somit die übrigen führen kann. Aus einer Statistik geht hervor, daß wenn die Standards eines Projekt-Managers durchgeführt wurden 76% des gesamten Projekts erfolgreich waren. Im Gegensatz dazu stehen 60%, wenn keinen Standards Folge geleistet wurde.
Ist eine Organisation sehr klein, kann der Software-Manager die Arbeit aus nächster Nähe betrachten und es ist keine SQS-Tätigkeit erforderlich. Steigt allerdings die Mitarbeiteranzahl, verliert der Manager schnell den Kontakt zur alltäglichen technischen Arbeit. In diesem Fall muß er eines der folgender Dinge tun:
- jemanden finden der seine Arbeitsbelastung in die Hand nimmt, damit er selbst die Arbeit seiner Leute wieder aus nächster Nähe betrachten kann
- jemanden einstellen, der die Prüfungsarbeiten erledigt
- die Leute motivieren, damit sie sich gegenseitig überwachen
Vom technischen, wirtschaftlichen und moralischen Standpunkt ist die letzte Möglichkeit die beste. Leider ist diese Organisation aufgrund zu großer Mitarbeiterzahlen kaum mehr möglich. Dann sucht das Management Zuflucht bei der SQS.
Grob gesagt sind die Ziele der SQS folgende:
- Verbesserung der Softwarequalität durch die Beobachtung des Software- und des Entwicklungsprozesses
- volle Übereinstimmung mit den festgesetzten Standards und Prozeduren für die Software und die Softwareprozesse
- Sicherstellung, daß jegliche Unzulänglichkeiten im Produkt, im Prozeß oder in den Standards sofort dem Management gemeldet werden, damit sie ausgebessert werden können
Die SQS-Organisation ist nicht für die Produktion von Qualitätsprodukten oder für die Erstellung von Qualitätsplänen verantwortlich, dies sind Aufgaben der Entwicklung. Die SQS ist dafür verantwortlich, daß die Qualitätsaktionen geprüft werden und im Falle eines Fehlers, dieser sofort an das Management weitergeleitet wird.
Möchte die SQS wirkungsvoll sein, muß sie eng mit der Entwicklung zusammenarbeiten. Sie muß die Pläne verstehen, die Ausführungen prüfen und die Erfüllung der individuellen Aufgaben überwachen. Wird die SQS von der Entwicklung als Feind angesehen, wird sie wohl kaum wirkungsvoll sein können. Ist die Entwicklung gegenüber der SQS willkürlich, feindselig und kleinkariert, kann dies durch eine noch so große Unterstüztung durch das Management nicht wieder gut gemacht werden.
Die einzigen Leute die für die Qualität eines Produktes verantwortlich sind, sind diejenigen die für die Softwareprojekte verantwortlich sind. Die SQS hat nun die Aufgabe, die Art mit der die Gruppen ihre Verantwortung erfüllen, zu überwachen.
Hier gibt es einige Fallen:
- es ist ein Fehler anzunehmen, daß die Leute von der SQS irgendetwas für die Qualität tun können
- existiert eine SQS, ist trotzdem nicht gesichert, daß den Standards und Prozeduren gefolgt wird
- das Management muß immerwieder seine Unterstützung der SQS offen darstellen, da sonst die SQS uneffizient wird
- das Management muß die SQS und das Projektmanagement dazu veranlassen, daß sie ihre Streitfragen beseitigen, bevor es zur Eskalation kommt, da sonst die SQS und die Entwicklung nicht effizient zusammenarbeiten können
Die SQS kann dann effektiv sein, wenn sie mit den richtigen Leuten besetzt ist und wenn sie ihre Rolle als Unterstützung der Entwicklung und zur Aufrechterhaltung der Verbesserung der Produktqualität erfüllt.
Dazu müssen sie folgende Verantwortungen übernehmen:
- alle Entwicklungs- und Qualitätspläne werden auf Vollständigkeit geprüft
- alle Testpläne überprüfen, ob an den Standards festgehalten wurde
- Überprüfung eines bedeutenden Beispiels auf alle Testergebnisse um das Festhalten am Plan zu ermitteln
- periodisches Überprüfen der SCM-Vorführung um das Festhalten an den Standards zu ermitteln
- teilnehmen an allen vierteljährlichen Projekt- und Phasenüberprüfungen und registrieren von Nichtübereinstimmungen, falls die angemessenen Standards und Prozeduren nicht sinnvoll eingesetzt wurden
Hier sind einige Beispiele von Prüfungs- und Berichtsmöglichkeiten, die die SQS vorführen könnte:
1. SQS versichert, daß eine nachweisbare Anforderungsmatrix oder ein ähnliches Werkzeug gebraucht wird um zu zeigen, daß die Produktspezifikationen die Bedürfnisse decken
2. SQS prüft nach, daß eine nachweisbare Implementierungsmatrix oder ein ähnliches Werkzeug gebraucht wird um zu zeigen, daß die Produktspezifikationen in das Design implementiert sind
3. SQS prüft Dokumentationsbeispiele um nachzuprüfen ob sie unter Zugrundelegung der Standards produziert und gewartet werden
4. SQS prüft angemessene Beispiele von den Entwicklungsberichten um sicher zu gehen, daß sie richtig gewartet werden und hinreichend das Software-Design darstellen
Werden SQS-Funktionen gebildet, sollte der grundlegende organisatorische Aufbau folgendes enthalten:
- Qualitätssicherungspraxis
Hinreichend entwickelte Instrumente, Techniken, Methoden und Standards sind definiert und erhältlich zum Gebrauch als Standards zu Qualitätssicherungsberichte.
- Softwareprojektplanungsauswertung
Werden nicht genügend Qualitätpraxen bereits am Anfang geplant, werden sie nicht ausgeführt werden.
- Bedürfnisberechnung
Da qualitativ hohe Produkte selten aus qualitativ niedrigen Bedürfnissen entstehen, müssen die anfänglichen Bedürfnisse auf die Anpassung an die Qualitätsstandards geprüft werden.
- Auswertung des Designprozesses
Mittel sind notwendig um sicherzustellen, daß das Design der geplanten Methode folgt, daß es die Prüfungen ausführt, und daß die Qualität des Designs unabhängig geprüft wird.
- Auswertung der Codierpraxis
Angemessene Codierpraxen müssen geschaffen und verwendet werden
- Auswertung der Softwareintegration und des Testprozesses
Ein Qualitätstestprogramm muß entwickelt werden; das Testen wird durch eine unabhängige Gruppe durchgeführt, die motiviert und fähig ist Probleme zu finden; das Testplanen beginnt früh; und die Qualität des Testens selbst wird geprüft.
- Bewertung des Managements im Prozeß und Projektkontrollprozeß
Während der Sicherstellung, daß die Managementprozesse funktionieren, hilft SQS zu sichern, daß die ganze Organisation darauf konzentriert ist ein Qualitätsprodukt zu entwerfen.
- Zurechtschneiden der Qualitätssicherungsprozedur
Der Software-Qualitäts-Sicherungsplan sollte auf die einmaligen Anforderungen jedes Projekts zugeschnitten sein.
Die SQS sollte immer einer höheren Managementebene berichten, um zu den erforderlichen Prioritäten Zugang zu haben und von dieser, bei der Bereitstellung von Mittel und Zeit zum Festhalten der Hauptfehler, unterstützt zu werden. Üblicherweise ist es so, daß man die niedrigeren Ebenen leichter beeinflussen kann als die höheren Ebenen. Leider gibt es aber keine einfache Lösung, also sollte ein genauer Berichterstattungsebenenentschluß für jede Organisation festgelegt werden.
Hierzu gibt es einige wichtige Richtlinien:
- SQS sollte nicht dem Projektmanager berichten
- die Berichterstattung durch die SQS sollte irgendwo innerhalb der lokalen Labors oder der Werksorganisationen erfolgen
- es sollte nicht mehr als eine Managementposition zwischen der SQS und dem Senior-Location-Manager sein
- SQS sollte versuchen immer nur den Leuten zu berichten, die von ihrer Aufgabe her daran Interesse haben
Der erste Schritt, der unbedingt getan werden muß, ist, daß sich die SQS die Zustimmung zu ihren Zielen des Top-Managements sichern muß. Nur wenn sie dies getan hat, kann sie sich im Falle eines Streits mit dem Line-Management Unterstützung erwarten.
Die acht Stufen, die zum Starten eines SQS-Programms erforderlich sind, sind folgende:
1. Beginn des SQS-Programms
Die Schlüssel-Rollen von SQS sind definiert und das Management vertraut sie der SQS öffentlich an. Dies resultiert aus dokumentierten Zielen und Verantwortungen und einem identifizierten Führer.
2. Identifizieren der SQS-Fragen
Der SQS-Führer und das Anfangspersonal arbeitet mit dem Projektmanagement zusammen, um die Schlüssel-Fragen für die SQS-Aufmerksamkeit zu identifizieren.
3. Schreiben des SQS-Plans
Der SQS-Plan definiert die SQS-Prüfungen und Kontrolltätigkeiten und identifiziert die erforderlichen Standards und Prozeduren. Der SQS-Plan ist in die Projektpläne integriert.
Im allgemeinen ist es nicht sehr praktisch jede Entwicklungsaktion und jeden Produktpunkt zu prüfen, also sollte aus dem Plan das Probesystem hervorgehen, das die effizientesten SQS-Resourcen verwenden wird.
Einige Probemethoden sind zum Beispiel:
- Versichern, daß alle benötigten Design- und Codeinspektionen vorgeführt sind, und an einer ausgewählten Menge teilgenommen haben.
- Überprüfen aller Inspektionsberichte und Analyse derer, die außerhalb der gebildeten Kontrollimits liegen.
- Versichern, daß alle erforderlichen Tests vorgeführt sind und alle Testberichte erstellt sind.
- Untersuchen einer ausgewählten Folge von Testberichten zur Sicherheit und Vollständigkeit.
- Prüfen aller Bausteintestergebnisse und weiteres studieren der Daten an den Bausteinen mit einer Testgeschichte, die außerhalb der gebildeten Kontrollimits liegt.
4. Bilden der Standards
Die Standards und Prozeduren die SQS führen sind entwickelt und genehmigt. Alle speziellen Projektbestimmungen sind ebenfalls überprüft und genehmigt.
5. Bilden der SQS-Funktionen
Die SQS-Funktion ist besetzt um den gebildeten Plan vorzuführen.
6. Handhabungstraining und fördern des SQS-Programms
Das SQS-Personal ist mit dem SQS-Plan beauftragt und mit dem benötigten Training am Projekt und den SQS-Methoden. Angemessene Meetings und Prüfungen werden abgehalten um das Projektpersonal von dem Zweck und der Rolle der SQS in Kenntnis zu setzen.
7. Ausführen des SQS-Plans
Jede SQS-Schlüsselaktivität ist einem speziellen SQS-Personal zugewiesen, ein Plan ist entwickelt, die Managementüberwachung ist gebildet, und ein Fragenlösungssystem ist erfüllt.
8. Bewerten des SQS-Programms
Die SQS-Funktion wird periodisch geprüft um seine Effizienz in der Darstellung seiner Aufgabe festzulegen. Notwendige Korrekturen sind identifiziert und ausgeführt.
Eine Möglichkeit um SQS-Programme zu bewerten ist das Bilden eines Prüfungsteams, das periodisch zusammentrifft und dessen Mitglieder aus anderen SQS-Organisationen sowie aus den eigenen Reihen kommen können.
Jedes Entwicklungs- und Aufrechterhaltungsprojekt sollte einen SQS-Plan haben, der seine Ziele festsetzt, die SQS-Aufgaben durchführt, die Standards an welchen die Entwicklungsarbeit gemessen wird und die Prozeduren und die organisatorische Struktur enthält.
Die IEEE Standards zur SQSP-Vorbereitung beinhaltet folgenden Entwurf:
- Zweck
- Übergabedokumente
- Management
- Dokumentation
- Es sollte die Dokumentation beschrieben werden und wie sie überprüft wird.
- Standards, Praxis, Tagung
- Rückschau und Prüfung
- Software-Konfigurations-Management
- Problemberichte und Korrekturaktionen
- Tools, Techniken und Methoden
- Programm-Kontrolle
- Medien-Kontrolle
- Lieferantenkontrolle
- Aufzeichnungssammlung, Wartung und Aufrechterhaltung
Viele SQS-Organisationen sind fehlerhaft, weil sie zu viel Einwirkung auf die Software-Qualität haben. Einige der wichtigsten Gründe hierfür sind:
- SQS-Organisationen sind sehr selten mit genügend erfahrenen und wissenden Leuten besetzt.
Die Rekrutierung für die SQS ist schwer, weil Software-Profis typischerweise die Entwicklungsaufgaben bevorzugen und das Management möchte verständlicherweise die besten Designer für die Design-Arbeit beauftragen.
- Das SQS-Management-Team ist oft nicht fähig mit der Entwicklung zu verhandeln.
Dies hängt vom Kaliber des SQS-Managementteams ab, welches der Reihe nach geführt wird (von den Kalibern der SQS-Profi-Belegschaft).
- Die Abteilungsleitung unterstützt oft die Entwicklung vor der SQS mit einem großen Prozentsatz von Fragen.
Die Entwicklung ignoriert dann die SQS-Fragen und die SQS beschäftigt sich nur noch mit einer Reihe von unnötigen niveaulosen Debatten.
- Viele SQS-Organisationen arbeiten ohne passende Dokumente und genehmigten Entwicklungsstandards und Prozeduren.
Ohne irgendwelche Standards, haben sie keine gesunde Basis zur Beurteilung der Entwicklungsarbeit, und jede Streitfrage wird eine Angelegenheit von eigener Meinung. Die Entwicklung gewinnt ständig solche verallgemeinerten Debatten, besonders wenn die Pläne festgefahren sind.
- Software-Entwicklungsgruppen produzieren selten nachweisbare Qualitätspläne.
SQS ist dann eher in Argumenten von speziellen Fehlern gefangen als allgemeinen Qualitätsanzeigen. In solchen Fällen gewinnen sie zwar die Schlacht, aber verlieren jedes Mal den Krieg.
Gute Leute für die SQS zu bekommen ist eines der schwierigsten Probleme mit denen ein Software-Manager konfrontiert wird. Das Rotationsschema kann effizient sein, aber leider ist die Software-Entwicklung meistens sehr geschickt in der Versetzung ihrer schlechten Mitarbeiter zur SQS, und weigert sich dann auch diese Mitarbeiter wieder zurückzunehmen.
Eine mögliche Lösung wäre, daß alle neuen Entwicklungsmanager von der SQS befördert werden. So sollten sie zum Beispiel erst ein halbes Jahr in der SQS verbringen, bevor sie zur Managementunterstützung befördert werden. Obwohl diese Maßnahme etwas radikal ist, kann sie effizient sein.
In DoD-Verträgen ist es oft üblich eine getrennte unabhängige Nachprüfungs- und Gültigkeitserklärungsorganisation mit einbezogen zu haben. Ihre Rolle ist es, eine unabhängige Überwachung der Entwicklung zur Verfügung zu stellen. Hier kann leicht eine Verwechslung der Rollen von IV&V und SQS vorkommen, aber der Unterschied sollte eigentlich klar sein. SQS wird vom Entwicklungsmanagement dazu verwendet die eigene Organisation zu überwachen. IV&V hingegen tut zwar im wesentlichen das selbe, aber für den Kunden.
IV&V kann und sollte aus der Existenz der SQS Nutzen ziehen. Arbeitet die SQS effizient, erspart sich die IV&V die Wiederholung der Arbeit. IV&V sollte außerdem die Kundenwünsche in der Arbeit ausreichend wiederspiegeln.
Eine weitere wichtige Aufgabe von IV&V ist es zu sichern, daß die richtigen Fertigkeiten und Standpunkte vorhanden sind.
Die SQS kann nichts bewirken, außer man unterstützt sie.
Softwarequalität:
- die Ansprüche des Kunden müssen erfüllt werden (Spezifikation)
- Robustheit (nicht Abstürzen)
- Erweiterbarkeit (kein geschlossenes System)
- Kompatibilität
- Benutzerfreundlichkeit
- Performance (Schnelligkeit)
- Portabilität (DOS, UNIX)
SQS - Abteilung sorgt nicht für die Qualität (nicht für alles kompetent), sondern überprüft, ob unternehmensinterne Standards eingehalten werden. Der Fachmann muß daher gute Standards erstellen.
Bsp.:
neunkantige Muttern - SQS kontrolliert ob sie erzeugt werden, sorgt aber nicht für Nützlichkeit oder Absatzmöglichkeiten.
Die Geschäftsführung muß hinter der SQS stehen.
Psychologisch:
- keinen Rotstift verwenden
- nicht sagen: "das ist ein Fehler"
- nicht "Prüfling" nennen
Standards für:
- Oberflächen
- Verfahren
- Programmcodes
Verfahren durch Kommunikation (human testing):
- Codeinspektion:
Programmierer treffen sich und sprechen den Code Zeile für Zeile durch
- Walkthrough:
Rollenspiel, wo jeder einen Programmteil spielt
- Peer Rating:
6 bis 20 Programmierer. Tauschen Programme aus und kontrollieren sie gegenseitig auf Verständlichkeit, Wartbarkeit und Dokumentation
- Review:
Standards werden vom SQS - Menschen und dem Programmierer durchgenommen.
Das Testen sollte von den besten Programmierern durchgeführt werden.
OOP ist vor allem bei großen Programmen sehr hilfreich, da ein Objekt sehr leicht eingebungen oder verändert werden kann. Dies verbilligt vor allem große Softwareprojekte enorm, da der Wartungsaufwand erheblich reduziert werden kann.
Was ist ein Objekt überhaupt? Ein Objekt hat Eigenschaften, die dieses Objekt einzigartig machen.
D.h. Ein Computer beispielsweise wäre ein Objekt, er hat einen Prozessortyp, einen Bustyp, eine Gehäuseart, alle diese Attribute machen ihn (das Objekt) einzigartig.
Es stellt sich die Frage, wie die Daten zu speichern sind. Die beste Lösung ist eine Struktur, in der alle Daten, das Objekt betreffend, gespeichert werden. (1.Schritt in Richtung OOP).
Ein Objekt hat also eigene interne Daten (Instanz Variablen) und außerdem eigene Funktionen (Methoden), die nur für dieses Objekt gelten. D.h. Ein Objekt ist einfach eine Struktur in die noch ihre Funktionen direkt hinein geschrieben werden. (2. Schritt in Richtung OOP).
Damit das Programm weiß wie auf die einzelnen Daten zugegriffen werden darf, gibt es mehrere reservierte Wörter. Diese sind u.a. private, public, protected
public:
dieses Wort sagt aus, daß überall aus dem Programm und jedes Objekt auf die Daten, die mit private definiert sind, zugreifen dürfen.
private:
dies bedeuted, daß nur objekteigene Funktionen auf diesen Datenbestand zugreifen dürfen.
protected:
bei dieser Definition wird festgelegt, daß nur objekteigene Funktionen und Funktionen von Vererbungen dieses Objektes auf diese Daten zugreifen dürfen.
So ein Unterprogrammaufruf wird beim OOP auch als schicken einer Nachricht bezeichnet.
Wir rufen eine Methode auf, indem wir das Objekt nennen, einen Punkt setzen und die gewünschte Methode angeben.
z.B. Rechteck.füllen
Bei Strukturen ist die Gefahr, daß der Programmierer auf Datenbestände zugreift, die er zu diesem Zeitpunkt vielleicht gar nicht ändern können sollte, daher Datenkapselung (private, public, protected siehe später). D.h., die dafür definierten Funktionen ändern die Datenbestände eines Objektes (und sonst nichts, nur diese Funktionen).
Beispiel zu Klassen:
Oben wird eine Hierarchie von Objekten angeführt. D.h. in Lok muß keine Achsenanzahl mehr gespeichert werden, weil Lok ein Schienenfahrzeug ist und dort die Information zu Achsenanzahl gespeichert wird. Jedes Schienenfahrzeug muß demzufolge Achsen haben um als Schienenfahrzeug zu gelten. Wasserverbrauch wiederum wird nur bei Dampflok gespeichert, da eine E-Lok keinen Holzverbrauch aufweist.
Viele Objekte sind einander ähnlich, jedoch nicht ident. Um nicht jedes Objekt extra definieren zu müssen ® Vererbung. Man muß nur sagen, welches Objekt von welchem Objekt die Daten und Methoden erben soll und welche Daten und Funktionen zusätzlich enthalten sind.
(Siehe Beispiel mit Lokomotiven von vorhin.)
Wir vererben die Datenbestände und die Funktionen und können weitere hinzufügen.
Wir kennen Basis (Parent, Eltern) - Klassen und Sub (Child, Kinder) - Klassen
Eine Virtual Funktion ist ein Platzhalter, der festlegt, daß nach der Vererbung unbedingt, zum Beispiel, eine Funktion an dieser Stelle geschrieben werden muß.
Dynamisches Binden:
Objekte sind dynamisch, d.h. sie werden erst bei laufendem Programm erzeugt (constructor), bzw. gelöscht (destructor). Dies ist in etwa mit dem Speicherallocieren in C "malloc", welches letztes Jahr im Unterricht durchgenommen wurde, vergleichbar. Dies bringt den erheblichen Vorteil, daß beim Compilieren noch nicht genau feststehen muß an welche Stelle (im Assemblercode) gesprungen werden muß. An unklaren Stellen wird ein Platzhalter eingesetzt, der während der Laufzeit durch das Run-time Modul richtig interpretiert wird.
Anders gesagt bedeuted "D.B.": es muß bei Compilierung noch nicht feststehen, welches UP ausgeführt wird
z.B. bei benutzerabhängiger Eingabe (zeigt Pointer auf O1 oder O2)
z.B. printf <> cout
Polymorphie (Polymorphe arrays):
Bei einem normalen Feld können nur Daten gleichen Typs gespeichert werden (int). Da jedoch bei Objekten Pointer verwendet werden, können verschiedenste Objekte (bzw. Pointer auf diese) in einem Array gespeichert werden.
Auf den ersten Blick sieht es so aus als würden verschiedenste Objekte in einem Feld gespeichert werden können (z.B. verschiedene Eisenbahnen, Züge und Wagen); in Wirklichkeit wird jedoch jeweils nur ein Pointer auf ein Objekt gespeichert und dadurch wird die Polymorphie (Vielschichtigkeit, Vielgesichtigkeit) ermöglicht.
Garbage Collection:
d.h. Alle Objekte, auf die kein Pointer zeigt, werden aus dem Speicher gelöscht.
Datenkapselung (engl.: encapsulation)
Die meisten Funktionen sind vorhanden, um die Inhalte der Variablen zu schützen.
Klassenhierarchie (Vererbung von Datentypen und Methoden einer anderen Klasse in eine neue).
Dynamisches Binden: Wenn beim Programmstart noch nicht bekannt ist, welcher Code ausgeführt wird. Aber auch "cout"
Normalerweise wird immer nach einem Schlüssel sortiert, weil ein Schlüssel ein eindeutig identifizierbares Attribut ist. Die Schlüssel die nur ein Teil der Datensätze sind werden verwendet, um das Sortieren zu steuern. Die Aufgabe des Sortierverfahrens besteht darin, die Datensätze so umzuordnen, daß ihre Schlüssel, gemäß einer gewissen klar definierten Ordnung, geordnet sind.
Grundsätzlich werden zwei Sortiermethoden unterschieden:
· interne Sortiermethoden:
Trifft dann zu, wenn die zu sortierende Datei im Speicher untergebracht werden kann, oder wenn sie in Turbo Pascal in einem Feld (Array) gespeichert werden kann.
· externe Sortiermethoden:
Trifft dann zu, wenn das Sortieren auf einem Magnetband oder einer Magnetplatte erfolgt.
Wenn die zu sortierenden Datensätze zu groß sind sollte man es vermeiden sie zu verschieben, und man sollte das "indirekte Sortieren" anwenden. Hierbei werden die Datensätze nicht unnötigerweise umgeordnet, sondern vielmehr wird ein Feld von Zeigern (oder Indizes) so umgeordnet, daß der erste Zeiger auf den kleinsten Datensatz zeigt. Die Schlüssel können entweder mit den Datensätzen (wenn sie umfangreich sind) oder mit den Zeigern (wenn sie zu klein sind) gespeichert werden. Falls erforderlich können die Datensätze nach dem Sortieren umgeordnet werden.
Parameter der Leistungsfähigkeit:
· Laufzeit:
ist die Zeit, die ein Algorithmus dazu benötigt eine Anzahl von N Elementen zu sortieren.
· zusätzlicher Speicherbedarf:
Grundsätzlich lassen sich die Sortieralgorithmen in drei Typen einteilen:
- Verfahren, die am Ort sortieren und keinen zusätzlichen Speicher benötigen
- Verfahren, bei denen eine Darstellung mittels verketteter Liste benutzt wird, sodaß sie im Speicher N zusätzliche Worte für Listenzeiger benötigen.
- Verfahren, die so viel zusätzlichen Speicherplatz benötigen, um eine weitere Kopie des zu sortierenden Feldes zu speichern.
· Stabilität:
Ein Sortierverfahren wird stabil genannt, wenn es die Reihenfolge gleicher Schlüssel in der Datei beibehält.
Z.B. eine Menge von Schülern wird nach Noten sortiert (Noten = Schlüssel). Bei einer stabilen Methode sind die Schüler noch immer in alphabetischer Reihenfolge in der Liste aufgeführt; bei einer instabilen ist von einer alphabetischen Reihenfolge keine Rede mehr.
= Sortieren durch direktes Auswählen
Laufzeit:
Die meiste Zeit wird dafür aufgewendet, das kleinste Element in dem unsortierten Teil des Feldes zu suchen. Der Selection Sort benötigt ungefähr n²/2 Vergleiche und n Austauschoperationen.
Funktionsweise:
Sucht aus einem Feld das kleinste Element und tauscht es gegen das an erster Stelle stehende Element. Dann wird das zweitkleinste Element gesucht und gegen das an zweiter Stelle stehende Element getauscht. u.s.w. . bis das gesamte Feld sortiert ist.
Beschreibung:
In der 1. Zeile findet man das kleinste Element, nämlich den 1er und tauscht es mit dem an 1. Stelle stehenden Element, dem 8er.
In der 2. Zeile bleibt dann der 1er stehen, weil es ja kein kleineres Element mehr gibt. Man findet nun den 3er und tauscht es mit dem an 2. Stelle stehenden Element, dem 5er.
In der 3. Zeile bleiben nun der 1er und der 3er stehen und man findet das drittkleinste Element, den 5er und tauscht es mit dem an dritter Stelle stehenden Element, dem 9er, usw.
= Sortieren durch direktes Einfügen
Diese Methode des Sortierens wenden Menschen oft beim Kartenspielen an, um ihre Karten zu sortieren.
Laufzeit:
Der Insertion Sort benötigt im Durchschnitt ungefähr n²/4 Vergleiche und n²/8 Austauschoperationen und im ungünstigsten Fall doppelt so viele.
Funktionsweise:
Betrachtet wird ein Element nach dem anderen und jedes an seinem richtigen Platz, zwischen den bereits betrachteten, eingefügt.
Beschreibung:
In der 1. Zeile erscheint als erste Zahl der 8er, danach der 5er. Da der 5er vor dem 8er in der Reihenfolge der ganzen Zahlen steht, werden die beiden Zahlen vertauscht.
In der 2. Zeile sieht man den 5er, den 8er, den 9er und den 7er. Die ersten drei Zahlen stimmen in der Reihenfolge, nur der 7er nicht. Der 7er wird zwischen dem 5er und dem 8er eingefügt.
In der 3. Zeile findet man 1er, der nicht in die Reihenfolge 5,7,8,9 hineinpaßt. Der 1er wird vor dem 5er eingefügt, usw.
= Sortieren durch direktes Austauschen
Laufzeit:
Bubble Sort benötigt im Durchschnitt und im ungünstigsten Fall ungefähr n²/2 Vergleiche und n²/2 Austauschoperationen.
Funktionsweise:
Hier wird die Datei immer wieder durchlaufen und wenn das maximale Element gefunden wird, wird es mit jedem rechts von ihm stehenden Element getauscht; solange, bis es das rechte Ende des Feldes erreicht hat.
Beschreibung:
1. Durchgang:
In der 1. Zeile wird der 8er mit dem 5er verglichen und da sie nicht in der Reihenfolge stehen, werden sie vertauscht.
In der 2. Zeile wird der 8er mit dem 9er verglichen, da sie in gleicher Reihenfolge stehen, wird kein Tauschvorgang vorgenommen.
In der 3. Zeile wird der 9er mit dem 7er verglichen und vertauscht.
In der 4. Zeile wird der 9er mit dem 1er verglichen und vertauscht.
In der 5. Zeile wird der 9er mit dem 6er verglichen und vertauscht.
In der 6. Zeile wird der 9er mit dem 3er verglichen und vertauscht.
In der 7.Zeile steht nun das größte Element (=9) an letzter Stelle, aber von sortierten Zahlen ist noch keine Rede. Es wird daher noch ein Durchgang benötigt. Es müssen allerdings nur mehr 6 Elemente statt 7 Elemente durchsucht werden.
2. Durchgang:
Beim 2. Durchgang wird ganz genauso vorgegangen wie beim 1., bis wieder das größte Element an letzter bzw. an vorletzter Stelle steht, also vor dem 9er.
Bis jedoch das gesamte Feld sortiert ist, sind noch ein paar Durchgänge notwendig.
Wie man sieht, wandert immer das größte Element nach hinten. Dadurch sind nach jedem Durchgang nur mehr N-1 Elemente zu durchsuchen.
Das ist der große Vorteil des Bubble Sort.
Um den Vergleich der Methoden weiterzuführen, ist es erforderlich, die Kosten von Vergleichs- und Austauschoperationen zu analysieren, ein Faktor, der wiederum von der Größe der Datensätze und Schlüssel abhängt. Wenn zum Beispiel die Datensätze, wie in den obigen Implementationen, aus einem Wort bestehende Schlüssel sind, so dürfte ein Austausch (zwei Zugriffe auf das Feld) etwa doppelt so teuer sein wie ein Vergleich. In einer solchen Situation sind die Laufzeiten von Selection Sort und Insertion Sort grob gesagt, vergleichbar, während Bubble Sort doppelt so viel Zeit benötigt. (Tatsächlich dürfte Bubble Sort unter nahezu allen Umständen halb so schnell sein wie Insertion Sort!) Falls jedoch die Datensätze im Vergleich zu den Schlüsseln groß sind, ist der Selection Sort am besten geeignet.
Der Insertion Sort ist langsam, weil nur benachbarte Elemente ausgetauscht werden. Wenn sich zum Beispiel das kleinste Element zufällig am Ende des Feldes befindet, so werden N Schritte benötigt, um es dorthinzubekommen, wo es hingehört. Shellsort ist einfach eine Erweiterung von Insertion Sort, bei dem eine Erhöhung der Geschwindigkeit dadurch erzielt wird, daß ein Vertauschen von Elementen ermöglicht wird, die weit voneinander entfernt sind.
Der Grundgedanke besteht darin, die Datei so umzuordnen, daß sie die Eigenschaft besitzt, daß man eine sortierte Datei erhält, wenn man jedes h-te Element (bei beliebigen Anfangselement) entnimmt. Eine solche Datei wird h-sortiert genannt. Mit anderen Worten, eine h-sortierte Datei besteht aus h unabhängigen sortierten Dateien, die einander überlagern. Durch das h-Sortieren für große h können wir Elemente im Feld über größere Entfernungen bewegen und damit ein h-Sortieren für kleinere Werte von h erleichtern. Indem man eine solche Prozedur für eine beliebige Folge von Werten von h anwendet, die mit 1 endet, erhält man eine sortierte Datei: dies ist Shellsort.
Shellsort ist die bevorzugte Methode für viele Anwendungen des Sortierens, da es selbst für relativ große Dateien (etwa bis zu 5000 Elementen) eine akzeptable Laufzeit aufweist und nur ein sehr kurzes Programm erfordert, daß sich leicht zu laufen bringen läßt. Kurz gesagt, wenn es ein Sortierproblem zu lösen gibt verwenden wir grundsätzlich immer dieses Programm und entscheiden dann, ob sich zusätzlicher Aufwand lohnen würde, es durch ein kompliziertes Verfahren zu ersetzen.
Laufzeit:
Der Shellsort führt
niemals mehr als ![]() Vergleiche aus (für
die Distanzen 1, 4, 13, 40, 121, .).
Vergleiche aus (für
die Distanzen 1, 4, 13, 40, 121, .).
Es ist allerdings möglich, den Shellsort mit anderen Folgen von Distanzen noch effizienter zu machen. Doch ist es selbst für relativ große N schwer, das Programm um mehr als 20% schneller zu machen.
Funktionsweise:
Es wird eine Schrittreihenfolge gewählt (z.B.: 13-h). Vom ersten Element ausgehend wird jedes h-te Element herausgenommen und in die richtige Reihenfolge gebracht. Dieser Vorgang wird mit jedem Element durchgemacht bis man am Ende angelangt ist. Dann wird eine neue Schrittreihenfolge gewählt (kleiner als die erste z.B.: 5-h) und der Prozess beginnt von vorne.
,%20Spezifikation_files/image004.gif)
Beschreibung:
1. Durchgang: Schrittreihenfolge 5 wird gewählt. Es wird das 1. und das 6. Element verglichen und da sie sich in der richtigen Reihenfolge befinden wird nichts verändert. Es wird das 2. und das 7. Element verglichen und da sie sich nicht in der richtigen Reihenfolge befinden werden sie vertauscht. Es wird das 3. und das 8. Element verglichen und da sie sich in der richtigen Reihenfolge befinden wird nichts verändert. u.s.w. . bis am Ende angelangt
2. Durchgang: Schrittreihenfolge 3 wird gewählt. Es wird das 1. und das 4. Element verglichen und da sie sich in der richtigen Reihenfolge befinden wird nichts verändert. Es wird das 2. und das 5. Element verglichen und da sie sich nicht in der richtigen Reihenfolge befinden werden sie vertauscht. u.s.w. .bis am Ende angelangt
u.s.w. . bis das Feld sortiert ist
Der Quicksort ist das am häufigsten verwendete Sortierverfahren, weil es sehr einfach zu implementieren ist. Er wurde 1960 von C.A.R. Hoare entwickelt und wurde seither von vielen Forschern untersucht.
Der große Vorteil besteht darin, daß er am Ort abläuft, und das für das sortieren von N Elementen im Durchschnitt nur N log N Operationen erforderlich sind, und daß er eine extrem kurze innere Schleife besitzt.
Der Nachteil besteht darin, daß er rekursiv und störanfällig ist und, daß er im ungünstigsten Fall N² Operationen benötigt.
Es gibt nun bereits viele verbesserte Varianten von Quicksort die schneller, besser oder auch effizienter arbeiten als der Quicksort von 1960. Es gilt jedoch zu beachten, daß bei jeder Veränderung einer bestehenden Variante eine Vielzahl von Effekten auftreten können, die nicht beabsichtigt waren. Wenn eine Variante entwickelt worden ist, die von solchen Effekten frei zu sein scheint wird diese meist als Bibliotheks- oder Standardsortierprogramm genutzt. Wenn man jedoch den Aufwand, um sicher zu sein, daß die Implementation von Quicksort nicht fehlerbehaftet ist, nicht investieren will, so ist Shellsort durchaus eine sichere Alternative, die bei geringem Aufwand für die Implementation recht effizient abläuft.
Das nachfolgende Programm ist die allgemeine Darstellung eines Quicksorts:
procedure quicksort(l,r:integer);
var i:integer;
begin
if r>l then
begin
i:=partition(l,r);
quicksort(l,i-l);
quicksort(i+l,r);
end
end;
Die Partition funktioniert wie folgt:
Beschreibung:
Das Feld wird nun von rechts nach links und von links nach rechts durchgegangen. Die am weitesten rechts befindliche Zahl 23 wird als das zerlegende Element gewählt. Wenn man nun von rechts nach links geht, wird immer nur dann unterbrochen, wenn ein Element kleiner ist als die 23, d.h. bei der Zahl 10. Wenn man von links nach rechts geht wird immer nur dann unterbrochen, wenn ein Element gefunden wird, das größer ist als die Zahl 23, d.h. die Zahl 52. Bei den Zahlen 10 und 52 bleiben nun die Zeiger stehen. Die beiden Zahlen werden vertauscht. Der Zeiger ist in der Darstellung der nach oben zeigende Pfeil.
In der zweiten Zeile wird nun bei der Zahl 10 und der Zahl 52 weitergegangen. Wenn man von rechts nach links geht, trifft man auf die Zahl 22, die kleiner ist als die 23. Von links nach rechts trifft man auf die Zahl 37, die größer ist als die Zahl 23, d.h. die beiden Zahlen werden vertauscht.
In der dritten Zeile fängt man nun wieder bei 22 und 37 an. Geht man von rechts nach links trifft man auf die Zahl 8, die kleiner ist als 23. Von links nach rechts trifft man auf die Zahl 5, die kleiner ist als 23, d.h. es wird weitergegangen bis zum 8er. Hier stoßen die beiden Zeiger zusammen.
Unser Feld ist getrennt. Man kann erkennen, daß alle Zahlen, die links von 23 stehen kleiner sind, und alle, die rechts von 23 stehen größer sind. Nun muß man das linke und das rechte Feld getrennt voneinander sortieren, und zwar genauso wie bis jetzt.
Beschreibung:
Hier ist unser auserwähltes Element die Zahl 8.
Nun geht man, wieder wie vorher, von rechts nach links, um ein Element, das kleiner als der 8er ist, zu finden. Hier sind wir gleich beim 5er angelangt. Der Zeiger bleibt auf dieser Position stehen.
Von links nach rechts sucht man ein Element, das größer ist als der 8er, nämlich gleich den 14er. Nun vertauscht man die beiden.
In der zweiten Zeile wird wieder vom 5er und vom 14er ausgegangen. Man sucht wieder ein kleineres und ein größeres Element als den 8er und tauscht sie aus, so lange, bis dieses Feld wieder geteilt ist. Man muß alle Teile sortieren, bis man sie sortiert zusammenhängen kann.
Ein Quicksort in Pascal würde wie folgt lauten:
procedure quicksort(l,r:integer);
var v,t,i,j:integer;
begin
if r>l then
begin
v:=a[r]; i:=l-1; j:=r;
repeat
repeat i:=i+1 until a[i]>=v;
repeat j:=j-1 until a[j]<=v;
t:=a[i]; a[i]:=a[j]; a[j]:=t;
until j<=i;
a[j]:=a[i]; a[i]:=a[r]; a[r]:=t;
quicksort(l,i-1);
quicksort(i+l,r);
end
end;
Die "innere Schleife" von Quicksort beinhaltet lediglich das Inkrementieren eines Zeigers und den Vergleich eines Feldelementes mit einem festen Wert. Eben das macht Quicksort so schnell, eine einfachere innere Schleife läßt sich kaum vorstellen. Dadurch hat jedes Hinzufügen auch nur eines überflüssigen Testes zur inneren Schleife einen spürbaren Einfluß auf die Leistungsfähigkeit.
Die am meisten störende Eigenschaft des obigen Programms ist, daß es für einfache Dateien sehr uneffizient ist. Wenn es z.B. für eine Datei aufgerufen wird, die bereits sortiert ist, so ruft sich das Programm selbst N mal auf.
Wenn in der Datei gleiche Schlüssel vorhanden sind, so treten zwei Besonderheiten auf. Erstens stellt sich die Frage, ob beide Zeiger bei Schlüsseln stehenbleiben sollten, die gleich dem zerlegten Element sind, oder ob ein Zeiger stehenbleiben und der andere sie durchlaufen sollte, oder ob beide Zeiger sie durchlaufen sollten. Am besten ist es, wenn man beide Zeiger anhalten läßt. Dies führt zu ausgeglichenen Zerlegungen, wenn viele identische Schlüssel vorliegen.
Eine Verbesserung von Quicksort ergibt sich aus der Beobachtung, daß ein rekursives Programm stets sich selbst für viele kleine Teildateien aufruft, daher sollte es eine möglichst gute Methode verwenden, wenn es kleine Teildateien verarbeitet. Ein offensichtlich möglicher Weg, um das zu erreichen, besteht darin, den Test zu Beginn des rekursiven Programms in der Weise abzuändern, daß Insertion Sort aufgerufen wird. Wenn der Insertion Sort aufgerufen wird, in einer Größenordnung zwischen 5 und 25, so läuft der Algorithmus ungefähr mit gleicher Effizienz ab. Die Verkürzung der Laufzeit liegt für die meisten Anwendungen in der Größenordnung von 20%.
Eine sehr spezielle Situation, für die ein einfacher Sortieralgorithmus existiert, wenn eine Datei mit N Datensätzen viele verschiedene Zahlenschlüssel hat. Die Idee besteht darin, die Anzahl der Schlüssel mit jedem Wert zu ermitteln und dann die Ergebnisse der Zählung zu verwenden, um bei einem zweiten Durchlauf durch die Datei die Datensätze in die richtige Position zu bringen.
Hier wird ein Feld mit lauter Nullen angelegt und darüber die Zahlen von 1 bis zur größten Zahl des zu sortierenden Feldes (in unserem Fall: 9) geschrieben.
Nun wird das zu sortierende Feld von links nach rechts durchgegangen. Das erste Element ist der 8er. Da es bis jetzt nur einen 8er gibt, zählt man 0 und 1 zusammen ® ergibt laut Adam Riese 1.
Diesen Einser schreibt man nun unterhalb des Nullers an die Stelle wo sich der 8er oberhalb des Nullers befindet.
Nun kommt man zum 5er und schreibt wiederum den Einser unterhalb des Nullers an die Stelle wo sich der 5er befindet, usw.
Wenn wir bei der letzten Stelle des zu sortierenden Feldes (=9) angekommen sind, sehen wir, daß es schon einen 9er gibt und zählt nun einfach zu dem Einser, der schon unterhalb des Nullers steht noch einen Einser dazu, welches 2 ergibt.
Nun sieht man ganz genau, daß es einen 1er, einen 3er, einen 5er, einen 6er, einen 7er, einen 8er und zwei 9er gibt.
Jetzt braucht man nur die Zahlen nach der Reihe aufschreiben.
key = 8000 byte 4 byte 10 byte
|
7 |
|
7 |
1 |
|
1 |
|
1 |
2 |
|
3 |
|
3 |
3 |
|
2 |
|
2 |
4 |
|
. |
|
. |
. |
|
. |
|
. |
. |
|
. |
|
. |
. |
|
. |
|
. |
. |
|
|
|
|
|
Hier arbeitet der Algorithmus indirekt (unter Verwendung eines Feldes von Indizes) mit der Datei und das Umordnen wird nachträglich vorgenommen.
|
1 |
2 |
3 |
4 |
|
|
1 |
2 |
3 |
4 |
|
|
|||||||||||||
|
7 |
1 |
3 |
2 |
|
|
7 |
1 |
3 |
2 |
|
® 1 2 3 7 |
|||||||||||||
|
1 |
2 |
3 |
4 |
|
|
2 |
4 |
3 |
1 |
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
Abb. 1 |
|
Abb. 2 |
|
|||||||||||||||||||||
Abb.1:
In der Mitte sind die zu ordnenden Zahlen: 7, 1, 3, 2
Oben und unten werden die zu sortierenden Zahlen einfach nach der Reihe mit Indizes beschriftet.
Abb.2:
Intern wurden die Zahlen schon sortiert, egal mit welchem Algorithmus, nur werden die sortierten Zahlen noch nicht dargestellt, weil es zu viel Zeit verbrauchen würde, Dateien mit großen Datensätzen zu sortieren.
In der Mitte stehen immer noch die zu sortieren Zahlen, oben auch noch immer die Indizes. Die unteren Zahlen geben einfach die Position der sortierten Zahlen an.
Wenn man die Abb. 1 noch einmal betrachtet sieht man, daß an 2. Stelle das kleinste Element, der 1er steht; an 4. Stelle steht das zweitkleinste Element, der 2er; an 3. Stelle steht der 3er und an 1. Stelle steht der 7er.
Unter Suchen wird das Wiederauffinden von Information aus einer großen Menge zuvor gespeicherter Informationen verstanden. Normalerweise wird Information in Datensätzen gespeichert, die einen Schlüssel besitzen, nach dem gesucht wird. Das Ziel ist es, alle Elemente aufzufinden, deren Schlüssel mit dem Suchschlüssel übereinstimmt.
Das Suchen benötigt bestimmte Datenstrukturen, diese kann man einfach mittels Wörterbücher erklären. Im Wörterbuch sind die Wörter die Schlüssel, und die Lautschrift, die Definitionen usw. die dazu gespeicherten Informationen.
Zur Datenstruktur gehört es aber auch, wie mit gleichen Schlüsseln umgegangen wird. Die erste Möglichkeit ist, in der Primärstruktur keine doppelten Schlüssel zuzulassen. Es ist dann aber notwendig, daß jeder Datensatz in der Primärstruktur eine Verkettung zu einer Liste mit den Datensätzen hat, die diesen Schlüssel haben. In der Primärstruktur könnten aber auch gleiche Schlüssel zugelassen werden. Es muß dann aber gewährleistet sein, daß alle Daten wieder aufgefunden werden können. Die letzte Möglichkeit besteht auf ein eindeutiges Kennzeichen jedes Datensatzes.
,%20Spezifikation_files/image006.gif)
Die Daten werden in einem Feld gespeichert und neue Datensätze werden am Ende angefügt. Beim Suchen wird jedes Element des Feldes nach dem anderen durchsucht, bis die Suche erfolgreich war, oder das Ende des Feldes erreicht wird.
Die sequentielle Suche in einem unsortierten Feld benötigt N+1 Vergleiche für eine erfolglose Suche, und durchschnittlich ungefähr N/2 Vergleiche für eine erfolgreiche Suche.
Verwendet man ein sortiertes Feld, so kann die Suche als erfolglos abgebrochen werden, wenn ein Schlüssel gefunden wird, der größer als der gesuchte Schlüssel ist.
Die sequentielle Suche in einem sortierten Feld benötigt sowohl für eine erfolgreiche aber auch für die erfolglose Suche ungefähr N/2 Vergleiche.
,%20Spezifikation_files/image008.gif)
Um die Suche zu beschleunigen kann man die am häufigsten benötigten Datensätze an den Beginn des Feldes stellen. Ist keine Information über die Häufigkeit vorhanden, kann man den zuletzt gesuchten Datensatz an den Beginn des Feldes stellen. Dies ist dann besonders effizient, wenn die meisten Zugriffe auf einen Datensatz eng aufeinander folgen.
Die Suchzeit kann gegenüber der sequentiellen Suche verringert werden, indem man ein sortiertes Feld durchsucht. Das Feld wird in zwei Hälften geteilt, und festgestellt in welcher Hälfte des Feldes sich der gesuchte Datensatz befindet. Diese Methode wird dann rekursiv angewandt, bis nur mehr ein Datensatz übrig ist. Dieser kann der gesuchte sein, oder den Datensatz mit dem gesuchten Schlüssel gibt es nicht. Im Beispiel wird nach der Zahl 13 gesucht:
,%20Spezifikation_files/image010.gif)
Binäre Suche erfordert sowohl für erfolgreiche als auch für erfolglose Suche niemals mehr als lg(N+1) Vergleiche.
Dies gilt, weil bei jedem Schritt die Anzahl der Datensätze halbiert wird. Ein Problem entsteht bei nicht eindeutigen Schlüsseln. Wenn während der Suche ein gesuchter Datensatz gefunden wird, müssen dann nämlich auch dessen Nachbarn durchsucht werden.
Die Folge der Vergleiche ist beim binären Suchen vorbestimmt, und kann in einem binären Baum dargestellt werden. Später werden noch Algorithmen beschrieben, die speziell konstruierte Baumstrukturen zur Steuerung der Suche benötigen.
Diese stellt eine mögliche Verbesserung dar. Hier versucht man genauer zu erraten, wo sich das gesuchte Element befindet. Dies erinnert an die Suche in einem Telefonbuch, wo man eher vorne zu suchen beginnt, wenn der gesuchte Name mit einem B beginnt. Im Beispiel wird wieder nach der 13 gesucht:
,%20Spezifikation_files/image012.gif)
Interpolationssuche erfordert für erfolgreiche aber auch für erfolglose Suche niemals mehr als lg[lg(N+1)] Vergleiche.
Die Interpolationssuche ist besonders für große, gleichmäßig verteilte Felder geeignet, da z.B. für eine Milliarde Elemente nur maximal 5 Schritte erforderlich wären. Ein Nachteil ist, daß die Interpolationssuche bei einer sehr ungleichmäßigen Verteilung hereingelegt werden kann. Bei kleinen Feldern ist auch der Vorteil, der durch die Interpolation entsteht, sehr gering.
Wie bereits bekannt ist, kann man die Folge der Vergleiche des binären Suchens in einem binären Baum darstellen. Die Idee ist nun, die Daten in einem Baum durch Verkettung zu speichern. Der Vorteil gegenüber der binären Suche ist, daß die Datenstruktur immer leicht wartbar ist. Es ist einfach ein neues Element einzubinden und ohne kompliziertes Herumschieben von Daten ist immer eine sortierte Struktur vorhanden.
Sie ist eine der fundamentalsten Methoden der Informatik. Trotz ihrer Einfachheit ist sie effizient und wird daher sehr oft eingesetzt.
Ein Baum ist dadurch definiert, daß jedes Glied genau ein übergeordnetes hat. Ein binärer Baum hat zusätzlich noch die Eigenschaft, daß jeder Knoten eine linke und eine rechte Verkettung hat. Beim binären Suchen wird weiters davon ausgegangen, daß alle Datensätze mit einem kleineren Schlüssel im linken Unterbaum und alle größeren und gleichen im rechten Unterbaum sind.
Bei der Suche vergleicht man den gesuchten Schlüssel mit der Wurzel, und geht dann in den entsprechenden Unterbaum, wo diese Vergleiche rekursiv fortgesetzt werden, bis die Gleichheit der Schlüssel erreicht ist, oder wenn der entsprechende Unterbaum leer ist.
Um einen Knoten hinzuzufügen, verfährt man wie beim erfolglosen Suchen, nur wird dann der leere Unterbaum durch den einzufügenden Knoten (I) ersetzt.
Ein Suchen oder Einfügen in einem binären Suchbaum erfordert durchschnittlich ca. 2 ln N Vergleiche, wenn der Baum aus N zufälligen Schlüsseln aufgebaut ist.
Die Laufzeit von Algorithmen, die binäre Suchbäume betreffen, sind stark von der Form der Bäume abhängig. Bei ausgeglichenen Bäumen kann sie sogar logarithmisch werden. Durch die Art des Aufbauens der Bäume können aber auch extrem ungünstige Bäume entstehen (A Z B Y C X oder A B C D E F ).
Im ungünstigsten Fall kann eine Suche in einem binären Suchbaum mit N Schlüsseln N Vergleiche erfordern.
Die bis jetzt behandelten Algorithmen waren recht unkompliziert im Vergleich zum Löschen einzelner Elemente aus einem binären Suchbaum. Hier kommt es nämlich darauf an, wo sich der Knoten befindet bzw. wieviele Nachfolger er hat. Hierzu ein Beispiel:
· Am einfachsten ist das Löschen eines Knotens ohne Nachfolger (C, L, P), weil nur eine Verkettung gelöscht werden muß.
· Beim Löschen von Knoten mit nur einem Nachfolger (A, R, H, M) muß dieser nur ausgekettet, und eine Verkettung zwischen dem Vorgänger und dem Nachfolger erstellt werden.
· Auch das Löschen eines Knotens, von dem einer der Nachfolger keinen Nachfolger hat (N), ist kein Problem, da man den Knoten durch diesen Nachfolger ersetzen kann.
· Das einzige Problem kann es weiter oben im Baum geben, wo jeder Nachfolger weitere Nachfolger besitzt. Das Löschen eines solchen Knotens (E) erfolgt in drei Schritten:
1. Suchen des nächstgrößeren Knotens (H); dieser kann nur einen Nachfolger haben
2. Ausketten dieses Knotens (nach den oben genannten Methoden)
3. Ersetzen des zu löschenden Knotens durch den größeren
Nachteil dieser Funktion ist, daß bei vielen "Löschen - Einfügen" Paaren ein leicht unausgeglichener Baum entsteht. Dieses Problem kann man mittels "lazy deletion" lösen. Hier wird ein Knoten nicht wirklich gelöscht, sondern nur als gelöscht markiert, und dadurch die Baumstruktur erhalten. Das Problem, das dabei entsteht, ist die Vergeudung der Zeit. Dies kann durch regelmäßiges Neuaufbauen des Baumes, mit Weglassen der markierten Knoten, verhindert werden.
Für viele Anwendungen benötigt man die Suchstruktur ausschließlich zum Suchen, und nicht zum Herumschieben von Datensätzen. Ein Beispiel wäre ein Feld mit allen Datensätzen mit Schlüsseln. Hier könnte man den Feldindex des Datensatzes suchen, der mit einem bestimmten Schlüssel übereinstimmt. So könnte man auch einen Datensatz mit einem bestimmten Index aus der Suchstruktur entfernen, ihn aber trotzdem noch im Feld behalten.
Ein Weg zur Indirektheit wäre, wenn man auf die Verkettung zugunsten eines Feldes verzichtet. Im Feld müssen dann die drei folgenden Attribute vorhanden sein:
· Schlüssel
· linker Nachfolger
· rechter Nachfolger
Diese Methode wird oft bevorzugt, da man sich das Speicherzuweisen erspart. Der Nachteil ist, daß unbenutzte Verkettungen Platz im Feld vergeuden.
Die zweite Möglichkeit liegt in der Festlegung von drei Feldern für Schlüssel, linker und rechter Nachfolger. Man kann leicht zusätzliche Felder (Information) hinzufügen, ohne das Programm für die Baumoperationen ändern zu müssen. Der Zugriff auf solche Felder erfolgt über den Index.
Dieser Algorithmus behandelt in erster Linie die Platzreduzierung und erst in zweiter Linie behandelt er die Zeitreduzierung. Diese Technik heißt auch Kodierungsmethode.
Im allgemeinen haben Dateien einen hohen Grad an Redundanz. Die Verfahren, die wir untersuchen, sparen Platz da die meisten Dateien einen relativ geringen Informationsgehalt haben.
Einsparungen kann man bei einer Textdatei von 20% bis 50% haben, bei einer binären
Datei hat man jedoch Einsparungen von 50% bis 90%. Doch es gibt auch Datentypen, bei denen man nur wenig einsparen kann, solche die aus zufälligen Bits bestehen.
Tatsächlich ist es so, daß Mehrzweck-Verfahren gewisse Dateien verlängern müssen, den sonst könnte man das Verfahren wiederholen und dadurch beliebig kleine Dateien erzeugen.
Man spricht hier von einem Lauf (run) dann, wenn sich lange Folgen sich wiederholender
Zeichen darstellt.
1. Methode bzw. Bsp.:
AAAABBBAABBBBBCCCCCCCCDABAAABBBBCCCD
Diese Zeilenfolge kann viel Kompakter kodiert werden, indem man die wiederholenden Zeichen nur einmal angibt und die Anzahl der Wiederholungen davor schreibt.
Also würde dann unser Bsp. kodiert so aussehen:
4A3B2A5B8CDABCB3A4B3CD
Bei einem Bitraster würde die Lauflängenkodierung so aussehen:
2. Methode bzw. Bsp.:
000000000000000000000000000111111111111111000000000 28 14 9
000000000000000000000000001111111111111111110000000 26 18 7
000000000000000000000001111111111111111111111110000 23 14 4
000000000000000000000011111111111111111111111111000 22 26 3
000000000000000000001111111111111111111111111111110 20 30 1
000000000000000000011111110000000000000000001111111 19 7 18 7
000000000000000000011111000000000000000000000011111 19 5 22 5
000000000000000000011100000000000000000000000000111 19 3 26 3
000000000000000000011100000000000000000000000000111 19 3 26 3
000000000000000000011100000000000000000000000000111 19 3 26 3
000000000000000000011100000000000000000000000000111 19 3 26 3
000000000000000000001111000000000000000000000001110 20 4 23 3 1
000000000000000000000011100000000000000000000111000 22 3 20 3 3
011111111111111111111111111111111111111111111111111 1 50
011111111111111111111111111111111111111111111111111 1 50
011111111111111111111111111111111111111111111111111 1 50
011111111111111111111111111111111111111111111111111 1 50
011111111111111111111111111111111111111111111111111 1 50
011000000000000000000000000000000000000000000000011 1 2 46 2
Hier in diesem Bitraster sieht man rechts eine Liste von Zahlen, die einen Buchstaben in einer kompremierten Form speichern können.
Man gibt nun links davon die jeweiligen Häufigkeiten an wie oft nun diese Null oder Eins
vorkommt, z.B.: in der ersten Zeile, sie besteht aus 28 Nullen, 14 Einsen und dann folgen wieder
9 Nullen, usw. geht es mit den anderen Zeilen.
Man sieht also, daß es wesentlich besser ist, die kodierte Form zu übergeben, als die unkodierte
und man kann auch so wieder den Bitraster rekonstruieren.
Man hat dadurch eine recht große Einsparung, denn man benötigt 975 Bits bei unkodierter Darstellung verwenden, aber jedoch nur 384 Bits bei der kodierten Darstellung, das ergibt eine Einsparung von 591 Bits.
Dieses Datenkompressionsverfahren spart beträchtlich Platz bei Textdateien.
Nehmen wir an wir wollen eine Zeichenfolge "ABRACADABRA" kodieren, und dieses mit dem herkömmlichen Verfahren des binären-Codes, bei einer Binärdarstellung mit Hilfe von 5 Bits zur
Darstellung eines Buchstabens.
Dann lautet die Bitfolge so:
0000100010100100000100011000010010000001000101001000001
Um diese zu dekodieren, nimmt man sich 5 Bits her und wandelt sie nach dem Binärcode um.
Nun ist dieses ziemlich unpraktisch, denn der Buchstabe D kommt nur einmal vor und der Buchstabe A jedoch 5 mal und man muß A jedesmal, die selbe Bitfolge, aufschreiben und wieder dekodieren.
Es wäre doch besser, wenn man versuchen würde, häufig verwendete Buchstaben eine kürzere Bitfolge zuzuweisen, indem man sagt A wird mit 0 kodiert, B mit 1, R mit 01, C mit 10 und D
mit 11, so daß dann aus ABRACADABRA dann diese
0 1 01 0 10 0 11 0 1 01 0
Bitfolge dann werden würde. Diese ist schon wesentlich kürzer denn diese Bitfolge benutzt nur mehr 15 Bits anstatt 55 Bits, so wie die vorhergehende. Dieser Code hat jedoch einen Haken, denn es ist kein wirklicher Code, da er abhängig ist von den Leerzeichen, ohne diese Leerzeichen würde nämlich
010101001101010 als
RRRARBRRA heraus kommen.
Also muß man die Zahl mit Begrenzern dekodieren, aber dann noch ist die Zahl von 15 Bits plus
10 Begrenzern noch immer kleiner als der Standard-Code.
Wenn kein Zeichencode mit dem Anfang eines anderen übereinstimmt werden keine Begrenzer benötigt. Deswegen werden wir die zu kodierenden Buchstaben anders wählen, nämlich:
A mit 11, B mit 00, C mit 010,D mit 10 und R mit 011
so gäbe es nur eine Möglichkeit, die 25 Bits Zeichenfolge
1100011110101110110001111
zu dekodieren.
Eine noch einfachere Methode zur Darstellung eines Codes ist ein Trie.
Dazu ein Bsp.: Wir wollen wieder ABRACADABRA kodieren, aber dieses mal mit dem Trie.
Dazu sollte man wissen, daß man bei einem Trie immer von der "Wurzel"
ausgeht und so sein Zeichen bestimmt. Wenn man bei einem Knoten angelangt
ist, muß man sich entscheiden ob nach links oder rechts.
Für links muß man mit 0 codieren und für rechts mit 1.
Nun, man sieht hier, daß der rechte Code um 2 Bits kürzer ist als der linke.
Die Trie-Darstellung garantiert also, daß kein Code für ein Zeichen mit dem Anfang eines anderen Zeichen übereinstimmt, so daß sich die Decodierung für die Zeichenfolge eindeutig
festlegen läßt.
Doch welchen Trie soll man Benutzen? Hier gibt es eine Lösung bei der man bei gegebener Zeichenfolge einen Trie berechnen kann und der eine minimale Bitfolge hat.
Dieses Verfahren wird Huffman Kodierung genannt.
Bei dem Erzeugen des Huffman-Codes kommt es in erster Linie darauf an wieviel Zeichen zu decodieren sind plus Leerzeichen. Nun ermittelt das folgende Programm die unterschiedliche Häufigkeit der Buchstaben eines Zeichenfeldes, und trägt sie dann in ein Feld count[0-26] ein.
Nun wieder ein Beispiel das wir kodieren , die Zeichenfolge lautet:
"A SIMPLE STRING TO BE ENCODED USING A MINIMAL NUMBERS OF BITS".
Der erste Schritt ist der Aufbau eines Tries entsprechend seiner Häufigkeiten, dazu sollte man
sich eine Buchstabentabelle machen.
|
|
|
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
|
k |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
|
count [k] |
11 |
3 |
3 |
1 |
2 |
5 |
1 |
2 |
0 |
6 |
0 |
0 |
2 |
4 |
5 |
3 |
1 |
0 |
2 |
4 |
3 |
2 |
0 |
0 |
0 |
0 |
0 |
Danach kann man schon mit dem Trie beginnen Man fängt an, in dem man die Buchstaben (Knoten) mit der Häufigkeit 0 wegläßt, und alle anderen Knoten mit ihrer Häufigkeit in einer Ebene darstellt. Nun nimmt man die Knoten mit den niedrigsten Häufigkeiten und fasse sie zusammen. Man nimmt nun die nächst höhere Häufigkeit und fasse sie wieder zusammen, dies geht so lange weiter bis alle Häufigkeiten in einem Baum dargestellt sind.
Beachten muß man jedoch, daß sich die Knoten mit geringer Häufigkeit weit unten und Knoten mit hoher Häufigkeit weit oben im Baum befinden.
Die quadratischen Knoten sind Häufigkeitszähler und die runden Knoten sind Summen Knoten und lassen sich durch ihre Nachfolger wieder darstellen.
Bei der Implementation kommt es mehr darauf an den Huffman-Code richtig anzuwenden bzw.
die Vorausberechnung richtig zu rechnen, um daraus eine effiziente Kodierung zu bekommen.
Man sollte hier einen Trie finden der die Häufigkeit der Buchstaben berechnet oder Zeichen
verwendet, deren Häufigkeit in einem Pascal Programm auftretten z.B.: ; und dafür eine Bitfolge reserviert.
So ein Kodierungsalgorithmus kann mit Hilfe des Huffman Codes 23% Einsparung liefern.
Runlength: Abhängig von Zeichenfolge (häufig sind lange Folgen von selben Zeichen)
Hufman: Abhängig von Häufigkeiten (wenige Zeichen extrem häufig)
Beispiel für Runlength: 1
11
21
1211
111221
312211
Differential Encoding:
|
4,32 |
4,34 |
4,31 |
4,36 |
4,31 |
|
4,32 |
+0,02 |
-0,03 |
+0,05 |
-0,05 |
Pictureencoding:
|
Bild |
JPEG |
MPEG |
|
22 MB |
700 KB |
170 KB |
Predictive Encoding (Digitales Telefon):
|
Meßwert |
202 |
304 |
398 |
500 |
599 |
704 |
|
Schätzung |
200 |
300 |
400 |
500 |
600 |
700 |
|
Abweichung |
+2 |
+4 |
-2 |
0 |
-1 |
+4 |
Beim Telefon: Abweichung von der Sinuskurve
Adaptive Huffman Encoding:
· Sender schickt unkodiertes Beispiel
· Empfänger bildet Baum
· Sender sendet dann kodiert, nach dem Baum, der dem Empfänger bekannt ist.
Bei Hashing (zerhacken) handelt es sich um eine Methode für die direkte Bezugnahme auf Datensätze in einer Tabelle. Dies erfolgt mit Hilfe einer Funktion, die direkt aus dem jeweiligen Schlüssel die Adresse des zugehörigen Datensatzes errechnet.
Wenn man weiß, daß die Schlüssel nur ganze Zahlen von 1 bis N sind, kann beispielsweise der Datensatz mit dem Schlüssel 5 an der Tabellenposition 5 gespeichert werden.
Hashing ist eine Verallgemeinerung dieser Methode, wenn die speziellen Kenntnisse über die Schlüsselwerte nicht vorhanden sind.
Bei der Benutzung von Hashing sind zwei Punkte zu beachten:
1. Wahl einer geeigneten Hash-Funktion zur Berechnung der Tabellenadresse.
2. Da die Anzahl der verfügbaren Speicherplätze in der Regel geringer ist als die der möglichen Schlüssel, muß eine Funktion gewählt werden, die eine Doppelbelegung einer Adresse zuläßt. Die Art der Behandlung derartiger Kollisionen beeinflußt die Zugriffsdauer wesentlich.
Hashing ist ein guter Kompromiß zwischen Zeit- und Platzbedarf. Gäbe es keine Beschränkung des Speichers, könnte man jede beliebige Suche mit nur einem Zugriff auf den Speicher ausführen, wenn man den Schlüssel als Speicheradresse verwendet. Wenn es keine zeitliche Begrenzung gäbe, könnte man mit einem Minimum an Speicherplatz auskommen, indem man ein sequentielles Suchverfahren verwendet.
Hashing ermöglicht es, mit einem vertretbaren Maß an Speicherplatz als auch an Zeit auszukommen. Eine effiziente Nutzung der verfügbaren Speicherkapazität und ein schneller Zugriff auf den Speicher sind die vorrangigen Ziele jeder Hashing-Methode.
Benötigt wird eine Funktion, die Schlüssel (für gewöhnlich ganze Zahlen oder kurze Zeichenfolgen) in ganze Zahlen aus dem Intervall [0 M-1] transformiert, wobei M die Anzahl von Datensätzen ist, die in dem verfügbaren Speicher untergebracht werden kann.
Hierfür werden in der Literatur eine Vielzahl von Hash-Algorithmen vorgeschlagen. Eine der bekanntesten Funktionen ist das Divisionsrestverfahren.
Hier ist für M eine günstige Primzahl zu wählen, so daß für den beliebigen Schlüssel k der Wert des Schlüssels nach der Formel h(k) = k mod M berechnet wird. Dies ist ein sehr einfaches Verfahren, das sich häufig leicht realisieren läßt und eine gute Verteilung der Schlüssel ergibt.
Beispiel: Gegeben ist eine Tabelle mit einer Größe M=101. Mit Hilfe der oben stehenden Hash-Funktion soll für den vierstelligen Schlüssel ' A KEY' die Tabellenadresse berechnet werden.
Als erstes muß der Schlüssel in eine Zahl codiert werden:
|
|
A |
K |
E |
Y |
|
|
1 |
11 |
5 |
25 |
|
|
00001 |
01011 |
00101 |
11001 |
![]()
Hieraus ergibt sich die Binärzahl 00001010110010111001 = 44217
44217 mod 101 = 80
Somit wird der Schlüssel A KEY an die, von der Hash-Funktion berechneten, Position 80 in der Tabelle abgebildet.
Durch die Verwendung einer Hash-Funktion kann es vorkommen, daß mehreren verschiedenen Schlüsseln ein und dieselbe Adresse zugewiesen wird. Die Behandlung solcher Kollisionen kann auf verschiedenste Art und Weise geregelt werden.
Bei der getrennten Verkettung wird für jede Tabellenadresse eine verkettete Liste erzeugt, die jene Datensätze enthält, deren Schlüssel auf diese Adresse abgebildet werden.
Beispiel:
Da die Schlüssel, die auf ein und dieselbe Tabellenposition abgebildet werden, in einer verketteten Liste abgelegt werden, können sie ebensogut geordnet gespeichert werden. Diese Methode führt zu einer Verallgemeinerung des elementaren Listensuchverfahrens. Anstatt eine einzige Liste mit einem Listenkopf zu führen, werden bei der getrennten Verkettung M Listen mit M Listenköpfen geführt.
Allgemein gilt: Eine getrennte Verkettung verringert die Anzahl der Vergleiche bei einer sequentiellen Suche durchschnittlich um den Faktor M. Es wird jedoch zusätzlicher Platz für die Verkettungen beansprucht.
Bei einer Implementation der getrennten Verkettung wird für M gewöhnlich ein relativ kleiner Wert gewählt, damit kein großer zusammenhängender Speicherbereich belegt wird. Doch es ist sicher am besten, M genügend groß zu wählen, so daß die Listen kurz genug sind, damit die sequentielle Suche zur effizientesten Methode wird.
Als Faustregel gilt, M sollte etwa einem Zehntel der zu erwarteten Schlüssel entsprechen, so daß die Listen durchschnittlich je zehn Schlüssel enthalten.
Falls mehr Schlüssel als erwartet auftreten, dauern die Suchvorgänge ein wenig länger, bei weniger Schlüssel wurde vielleicht etwas mehr Speicherplatz verwendet.
Falls die Anzahl der Elemente, die in die Hash-Tabelle aufgenommen werden sollen, im voraus geschätzt werden kann, und falls ausreichend zusammenhängender Speicherplatz zur Verfügung steht, um alle Schlüssel aufzunehmen und noch zusätzlich Platz zu lassen, dann lohnt es sich nicht, irgendwelche Verkettungen zu verwenden.
Bei der offenen Adressierung wird im Kollisionsfall der Adreßbereich entweder in konstanten oder in quadratisch ansteigenden Abständen nach freiem Speicherplatz durchsucht.
Die einfachste Methode mit offener Adressierung wird lineares Austesten genannt. Im Falle einer Kollision wird einfach die nächste Position in der Hash-Tabelle untersucht. Ist diese leer, können die Daten dort gespeichert werden. Wenn auch diese Position belegt ist, wird wieder die nächste Position untersucht, solange bis eine leere Position erreicht wurde.
Beispiel:
,%20Spezifikation_files/image022.gif)
Der Umfang der Tabelle für lineares Austesten ist größer als für getrennte Verkettung, doch die Gesamtgröße des verwendeten Speicherplatzes ist geringer, da keine Verkettungen benutzt werden.
Allgemein gilt: Für eine Hash-Tabelle, die zu weniger als zwei Dritteln gefüllt ist, erfordert lineares Austesten im Durchschnitt weniger als fünf Tests.
Da beim linearen Austesten auch andere Schlüssel untersucht werden, speziell dann, wenn sich die Tabelle zu füllen beginnt, kann das eine drastische Erhöhung der Suchzeit bewirken. Solche Anhäufungen sorgen dafür, daß lineares Austesten für fast volle Tabellen sehr langsam abläuft.
Mit Hilfe des doppelten Hashing kann dieses Problem praktisch beseitigt werden. Beim Hash-hash-Verfahren wird im Kollisionsfall, zur Suche eines freien Speicherplatzes, wieder eine Hash-Funktion verwendet, die sich von der ersten unterscheiden sollte (auftreten würde). Ansonsten ist dieses Verfahren das geeignetste, um die Anzahl der Kollisionen gering zu halten.
Für das folgende Beispiel wurde folgende Funktion als zweite Hash-Funktion verwendet:
h2 = 8 - (k mod 8).
Beispiel:
,%20Spezifikation_files/image024.gif)
Allgemein gilt: Doppeltes Hashing erfordert im Durchschnitt weniger Tests als lineares Austesten.
Methoden der offenen Adressierung können in einer dynamischen Situation, bei der eine nicht vorhersagbare Anzahl von Einfüge- und Löschoperationen auszuführen sind, unzweckmäßig sein. Es muß beim Löschen mit Vorsicht vorgegangen werden, da ein Datensatz nicht einfach aus einer Tabelle entfernt werden kann, die mit Hilfe von linearem Austesten oder doppeltem Hashing erzeugt wurde. Es würde eine Lücke entstehen, die bei der Suche nach einem anderen Datensatz dazu führt, daß an dieser Stelle abgebrochen wird, anstatt weiterzusuchen. Eine Lösung dieses Problems wäre, spezielle Platzhalter zu verwenden.
Zu beachten ist, daß bei der getrennten Verkettung das Löschen eines Datensatzes kein besonderes Problem darstellte.
Die Wahl der besten Hashing-Methode, für eine spezielle Anwendung, kann sehr kompliziert sein. Im allgemeinen besteht die beste Strategie darin, die Methode der einfachen getrennten Verkettung anzuwenden, um die Suchzeit stark zu verkürzen, wenn die Anzahl der zu verarbeitenden Datensätze nicht im voraus bekannt ist, und doppeltes Hashing zu verwenden, um eine Menge von Schlüsseln zu suchen, deren Größe im voraus grob angegeben werden kann.
Aus dem Schlüssel soll erkennbar sein, wo der Datensatz gespeichert ist. Dies geschieht mittels Hashfunktion
Separate Chaining:
Linear Probing (Buketts von Länge 1):
Double Hashing: Cluster vermieden, indem nicht in nächstes, sondern auf eines gesprungen wird, das durch zweite Hashfunktion berechnet wird.
· bei binären Bäumen tritt der ungünstigste Fall relativ häufig ein. (geordnete Dateien, umgekehrter Reihenfolge, abwecheselnd großer, kleiner Schlüssel, usw.)
· Ausgleichen verhindert das Eintreten des ungünstigsten Falls.
· Ausgleichen dient als Grundlage für ausgeglichene Bäume.
· mehr Flexibilität gegenüber herkömmlichen binären Suchbäumen durch 3-Knoten und 4-Knoten.
· 2-Knoten enthalten 1 Schlüssel
· 3-Knoten enthalten 2 Schlüssel
· 4-Knoten enthalten 3 Schlüssel
· Suchen, Einfügen und Aufspalten.
Suche nach G:
mittlere Verzweigung, da G zw. E und R
links, da G nicht vorhanden und Suche von links beginnt.
Einfügen von G:
Zuerst erfolglose Suche durchführen, dann G anhängen.
drei Möglichkeiten:
· 2-Knoten: G wird angehängt. aus 2 wird 3.
· 3-Knoten: G wird ebenfalls angehängt. aus 3 wird 4.
· 4-Knoten: G wird mit dem ihm am nächsten Element zusammengezogen und bildet mit diesem einen 3-Knoten, ein Element wird nach oben geschoben, wobei die hier angeführten Regel zu berücksichtigen sind. Aus dem vierten Element wird ein 2-Knoten gebildet.
Aufspaltung eines 4-Knotens, wenn Vorgänger ebenfalls 4-Knoten:
Es besteht die Möglichkeit, beim Einfügen eines neuen Knotens, den ganzen Baum (wenn notwendig) nach oben hin aufzuspalten. Nur wenn in der Wurzel ein 4-Knoten steht und dieser aufgespalten werden muß, wird der Baum um eine Stufe tiefer.
Aufspalten von Wurzelknoten:
1. I als mittlerer Wert bleibt als Wurzel in einem 2-Knoten bestehen.
2. E & R werden eine Ebene tiefer als zwei seperate 2-Knoten eingefügt.
Einfügen von D:
1. Suche von Pos. Erg. rechts von C.
2. Da C in 4-Knoten, Aufspaltung von EIR.
3. Erneute Suche von Pos. zw. CE
4. Einfügen des neuen 2-Knoten.
Der oben skizzierte Algorithmus zeigt, wie Suchvorgänge und Einfügungen in 2-3-4-Bäumen ausgeführt werden können. Da die 4-Knoten auf dem Weg von oben nach unten aufgespalten werden, werden diese Bäume TOP-DOWN 2-3-4 Bäume genannt. Interessant ist hier, daß diese Bäume vollkommen ausgeglichen sind, obwohl wir keinerlei Vorkehrungen dafür getroffen haben.
(Beim Suchen in 2-3-4-Bäumen mit N Knoten werden niemals mehr als lg N+1 Knoten besucht.)
Die Entfernung zur Wurzel ist immer gleich. Der Abstand ändert sich nur, wenn wir die Wurzel aufspalten, dann allerdings generell um eins.
(Einfügungen in 2-3-4-Bäume mit N Knoten erfordern im ungünstigsten Fall weniger als lg N+1 Aufspaltungen von Knoten und scheinen im Durchschnitt weniger als eine Aufspaltung eines Knotens zu erfordern.)
Der ungünstigste Fall in einem 2-3-4 Baum ist, wenn auf dem gesammten Weg von oben nach unten 4-Knoten vorhanden sind. Dies ist allerdings äußerst unwahrscheinich. Analytische Ergebnisse hinsichtlich des durchschnittlichen Verhaltens von 2-3-4-Bäumen konnten die Experten bisher noch nicht erzielen, doch empirische Untersuchungen zeigen übereinstimmend, daß sehr wenige Aufspaltungen durchgeführt werden.
Den oben beschriebenen Algorithmus könnte man schon jetzt implementieren, aber er würde einen ziemlichen Wulst an Routinen nach sich ziehen. Bei komplexeren Baumstrukturen würde der 2-3-4-Baum langsamer werden als ein simpler binärer Suchbaum. Der Hauptzweck eines 2-3-4-Baumes ist die Versicherung gegen den ungünstigsten Fall. Es sollte allerdings nicht so sein, daß bei jedem Durchlauf dies auf Kosten der Geschwindigkeit geht. Darum wurden die Rot-Schwarz-Bäume entwickelt.
· 2-3-4 Bäume können als gewöhnliche binäre Bäume dargestellt werden, wobei nur ein zusätzliches Bit pro Knoten verwendet wird.
· 3-Knoten und 4-Knoten werden als kleine binäre Bäume dargestellt, die durch eine "rote" Verkettung gekennzeichnet sind.
· Alle anderen Verbindungen sind "schwarz".
· Es dürfen niemals zwei rote Verkettungen hintereinander auftreten.
· Das zusätzliche Bit pro Knoten wird benutzt, um die Farbe, der auf den betreffenden Knoten zeigenden Verkettung, zu speichern; 2-3-4-Bäume, die in dieser Weise dargestellt sind, werden als Rot-Schwarz-Bäume bezeichnet.
· Der Unterschied in der Implementierung ist nur, daß wir ein zusätzliches bool´sche Feld namens "red" erstellen müssen.
· Dieses bool´sche Feld wird von der Funktion, die den Baum durchläuft, ignoriert. Dies bedeutet, daß für das Suchen keine Anderungen zum binären Baum notwendig sind.
· Beim Aufspalten in einem Rot-Schwarz-Baum gibt es dieselben Möglichkeiten wie in einem 2-3-4-Baum (aus 4-Knoten mache drei 2-Knoten).
· Es treten Probleme auf, wenn ein 3-Knoten mit einem 4-Knoten verbunden ist und der 4-Knoten sich in der Mitte oder Links befindet:
· Lösung: Rotation! Kann leicht veranschaulicht werden (durch 2-3-4-Bäume), wie vorgegangen werden muß
.
· Es gibt die einfache Rotation (single Rotation) und die doppelte Rotation. Bei der einfachen Rotation sind die beiden roten Verbindungen in einer Richtung, bei der doppelten sind sie in entgegengesetzter Richtung. (siehe oben)
· (Eine Suche in einem Rot-Schwarz-Baum mit N Knoten, der aus zufälligen Schlüsseln aufgebaut wurde, scheint ungefähr lg N Vergleiche zu erfordern, und ein Einfügen scheint im Durchschnitt weniger als eine Rotation zu erfordern.)
· Die eigentliche Bedeutung von Rot-Schwarz-Bäumen liegt in ihrem Verhalten im ungünstigen Fall, sowie in der Tatsache, daß diese Leistungsfähigkeit mit sehr geringem Aufwand erreicht werden kann.
· (Eine Suche in einem Rot-Schwarz-Baum mit N Knoten erfordert weniger als 2 lg N+2 Vergleiche, und die Zahl der Einfügungen liegt unter einem Viertel der Zahl der Vergleiche.)
· Der ungünstigste Fall liegt vor, wenn der Pfad zum Ort des Einfügens aus sich abwechselnden 3- und 4-Knoten besteht.
kurz gesagt:
Bei Anwendung dieses Verfahrens kann ein Schlüssel in einer Datei, mit beispielsweise einer halben Million Datensätze, mit nur ungefähr zwanzig Vergleichen, mit anderen Schlüsseln gefunden werden.
Die älteste und bekannteste Datenstruktur für ausgeglichene Bäume ist der AVL-Baum. Diese Bäume haben die Eigenschaft, daß sich die Höhen der beiden Unterbäume jedes Knotens höchstens um eins unterscheiden. Falls diese Bedingung infolge einer Einfügung verletzt wird, so zeigt es sich, daß sie, unter Verwendung von Rotationen, wiederhergestellt werden kann. Dieser Algorithmus hat den Nachteil, daß erstens eine zusätzliche Schleife für die Rotation benötigt wird, und daß für jeden Knoten auch noch die Länge seiner jeweiligen Unterbäume gespeichert werden muß.
Eine zweite ausgeglichene Baumstruktur ist der 2-3-Baum, bei dem nur 2-Knoten und 3-Knoten zugelassen sind. Es ist möglich, ein Einfügen unter Verwendung einer "zusätzlichen Schleife" zu implementieren, wobei Rotationen wie bei AVL-Bäumen erforderlich sind, doch es ist nicht genügend viel Flexibilität vorhanden, um eine zweckmäßige Top-Down-Variante zu erhalten. Auch hier ist es möglich, daß eine Vereinfachung, unter Zuhilfenahme des Rot-Schwarz-Schemas, erreicht werden kann.
Es gibt auch noch einen anderen wichtigen Typ eines ausgeglichenen Baumes, eine Verallgemeinerung der 2-3-4-Bäume, die B-Bäume genannt werden. Diese gestatten bis zu M Schlüssel pro Knoten, und sie werden häufig für Suchanwendungen, bei denen sehr große Dateien auftreten, verwendet.
zusammengefaßt.
Haupt | Fügen Sie Referat | Kontakt | Impressum | Nutzungsbedingungen